
Contents
This topic focuses on the rules of execution order and the concurrency options available in StreamBase applications. This page presents an in-depth discussion of the principles supporting the concurrency options.
-
See Concurrency Options for the basics of setting the concurrency options for operators using the Concurrency tab of the Properties view for most operators.
-
See Dispatch Styles for the basics of using dispatch styles with multiplicity settings of two or more.
By default, when StreamBase processes data in an application, operations are executed in a predictable order and input tuples are each processed individually to completion. In EventFlow applications, the predictable order is from left to right in the EventFlow canvas.
If you know that portions of your StreamBase application can run without dependencies on the other streaming data in your application, you may be able to improve the overall throughput of the application by specifying that some portions of the application run in their own processing parallel regions. This can result in faster performance on multiprocessor machines, because multiple regions are automatically processed in parallel on the operating systems supported by StreamBase.
Important
There are a number of caveats associated with using the concurrency options. In StreamBase Studio, most operators have an optional Concurrency tab in their Properties views. Text in that tab cautions you that using concurrency options requires a thorough analysis of your application. Be sure to read the caveats described in Important Considerations for Using Multiple Multiplicity.
The StreamBase rules of execution order are as follows:
-
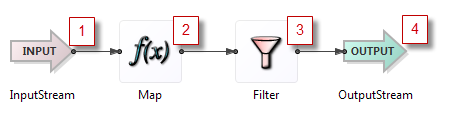
Rule 1: Each input tuple is processed to completion, from left to right.
When a tuple arrives at the input of an operator, it is processed as far as possible, upstream to downstream, before processing happens on any other tuples. To emphasize the point, the term processed to completion means that:
-
Whenever a tuple arrives on an input stream, it is processed to completion by the first operator tied to that input stream, and is then processed by the second operator (if any), and so on, downstream through the application.
-
Whenever a tuple arrives at an operator, the operator does its processing on that tuple, generating zero or more output tuples. The first output tuple is processed to completion, in order, by each downstream operator, in order; then the second output tuple is processed to completion by each downstream operator, in order; and so on.
-
Downstream operators finish work before the upstream operator or input stream sees another tuple.
-
-
Rule 2: Branches are processed sequentially.
If the path of tuple processing ever splits, the different branches are always executed one at a time, to completion, and in the same order for each tuple. If the sequence branches by means of a Split operator, the branches run in guaranteed order by output port number.
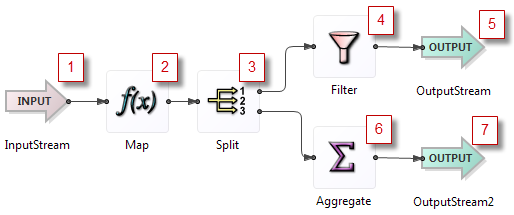
If an operator has multiple arcs exiting from one output port, the branches run sequentially in an undefined order. To achieve a deterministic ordering, inserting a split operator to fan out streams is recommended.
-
Rule 3: Output tuples are processed sequentially.
If an operator ever generates more than one tuple, each output tuple is processed to completion one at a time before the next one is considered.

-
Rule 4: Module output is processed to completion immediately.
Consider the case where you have a module named
Inner, which is inside a module namedOuter. The execution order is the same as if you had copied the entire verbatim contents ofInnerintoOuterat the point of the module reference. When a tuple emerges from one ofInner's output streams, that tuple becomes available inOutercompletely and is processed there to completion throughout the rest ofOuter.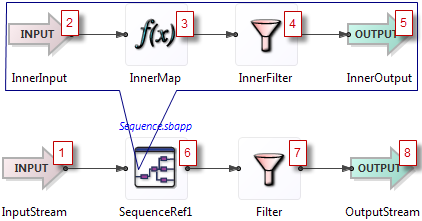
-
Rule 5: The path of execution never loops. Tuples queue rather than loop.
Application code may contain loops, but the path of execution never loops. When an input tuple reaches an operator that is upstream in the processing path, it is queued. When processing completes downstream of that operator, queued tuples are then processed to completion.
If a tuple is sent backwards on a loop (such as a Union operator with an explicitly-declared schema), downstream processing completes before the tuple is cycled again in the loop.
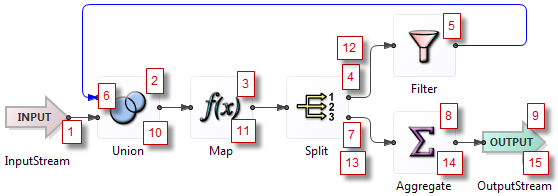
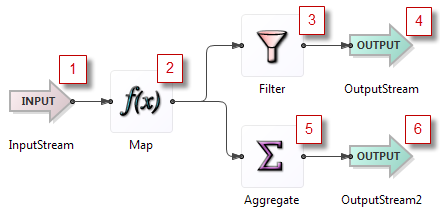
One tuple passes through the example module above as follows:
-
The illustrated module presumes that the Map operator increments a count field in the tuple and the Filter operator tests for reaching a threshold on that count.
-
The tuple passes through in steps 1 through 5 to the Filter operator.
-
The blue arc exiting the Filter operator back to the Union has an explicit schema declared, which allows the loop to pass typechecking. (See Arcs in Loops.)
-
At step 6, the tuple entering the Union operator from the Filter is held in a queue until the downstream processing completes.
-
Remember that a Split operator processes tuples in the known sequence of output port order. Thus, the next downstream operation is to go back to the Split operator and traverse the second output port, shown as step 7.
-
The tuple then passes through the Aggregate operator to the output stream, steps 8 and 9.
-
Now that the original downstream processing has completed, the copy of the tuple queued at step 6 can proceed down its path. This is shown as step 10, which is the continuation of the queued step 6.
-
The tuple now arrives through step 11 to the Split again. It first goes out the Split's port 1 to the Filter, where it fails the threshold test this time.
-
Next, the tuple traverses the Split operator's second port at step 13.
-
The tuple proceeds through the Aggregate operator to the Output stream in steps 14 and 15.
-
-
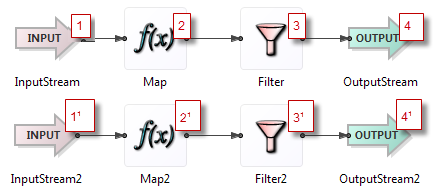
Rule 6: When multiple tuple sources are ready to be processed, the one to process is selected arbitrarily.
Tuple sources include input streams, Metronome operators, adapters, and so on. Data can arrive at one or more input streams during the processing of the previous data. When processing completes, the next tuple selected for processing on several queued tuple sources is chosen arbitrarily.
-
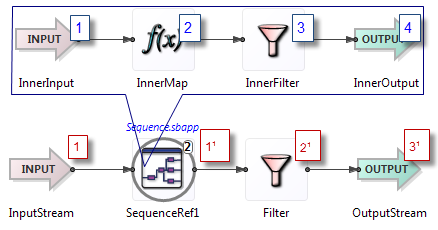
Rule 7: Multiple parallel regions can process tuples at the same time.
Each parallel region processes tuples independently. Thus, multiple tuples can be processed simultaneously if they are in separate regions.
-
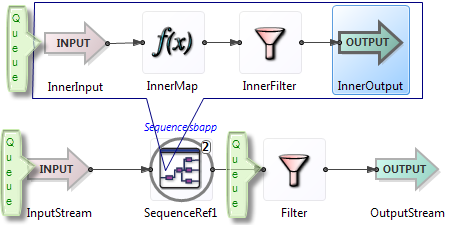
Rule 8: When a tuple crosses the boundary between parallel regions, it is queued.
StreamBase queues exist to manage the relative rate of consumption and production between modules and components. Queues will push back if the production rate of a component exceeds its consumption for too long.
-
Rule 9: Synchronous container connections are an exception to rule 8.
Synchronous container connections extend one parallel region into the connected parallel region, which excludes the possibility of simultaneous processing in both regions at the same time.
A parallel region is a collection of running StreamBase code, rooted at a particular instance of a module, that is guaranteed to process one tuple at a time, and to do so asynchronously from other parallel regions. (There is an exception for synchronous container connections, as described in Rule 9 of the previous section.)
Parallel regions and the Run this component in its own parallel region concurrency setting are closely related.
The following examples clarify the concept of parallel regions:
-
A simple running module, running in a container in StreamBase Server, with default concurrency settings, operates in a single parallel region. The StreamBase container is the most elementary parallel region. When you run an application with no concurrency in a container, it is in a parallel region, and the root of that region is the container.
-
A module,
Upper.sbapp, contains a Module Reference,Lower_Ref, to a separate module,Lower.sbapp. If the Module Reference has no concurrency settings, thenUpper.sbappruns in one parallel region. -
If you set the previous example's Module Reference to Run this component in its own parallel region, with no Multiplicity setting, then when you run
Upper.sbapp, there are two parallel regions: one for the code in Upper, and a second for that instance of theLower.sbappmodule. The root of the second parallel region is theLower_Refmodule reference, and the path to that region's root is[. For example:container-name].Lower_Refdefault.Lower_Ref. -
Let's say the Module Reference in
Upper.sbapp, in addition to the parallel region Concurrency setting, also has the Multiplicity = multiple setting with Number of instances = 2. When you runUpper.sbapp, there are three parallel regions: one for the code in Upper, and one each for each instance ofLower.sbapp. -
Another module might have one single operator, such as a Map operator, whose concurrency settings specify run in its own parallel region, Multiplicity = multiple, and Number of instances = 4. This module operates in five parallel regions: one for each instance of the concurrent Map operator, and another region for the rest of the module's code.
-
Yet another module might have a single operator, such as a Map operator, whose Concurrency tab leaves Run this component in a parallel region unselected, but then specifies Multiplicity = multiple and Number of instances = 17. This module operates in only one parallel region, and tuples are dispatched to whichever instance satisfies the dispatch expression. However, tuples do not enter separate parallel regions and therefore no inter-region queuing occurs.
-
Module, A, in the
defaultcontainer has a Module Reference,B_ref, to module B, and that reference is set for own parallel region and two multiple instances. Module B, in turn, has a Module Reference,C_ref, to module C, which reference is set for own parallel region and three multiple instances. Running the top-level module A results in up to nine parallel regions: one for module A's code, plus two for each instance of module B, plus six for each instance of module C (since both instances of module B can call up to three instances of module C).
See Operator Support for Concurrency Options for a table of Spotfire Streaming operators and adapters and the concurrency options supported by each.
Most operators have an associated Multiplicity setting that defaults to single, but which can be changed to multiple. In the case of single multiplicity, each tuple arriving at one of an operator's input ports is processed once.
In the case of multiple multiplicity, you also specify a number of instances. Each module instance is a separate copy of the module specified in the Module Reference, and each module instance has its own independent copy of the module's state, including Query Tables.
Important
StreamBase does not support exporting a Query Table from a Module Reference with a multiplicity setting greater than 1.
Each tuple arriving at one of a multiple component's input ports is passed to one instance or all instances, depending on the dispatch style of the input port. The dispatch style is a property you specify in the case of multiple multiplicity, or when using an Extension Point. Dispatch styles are discussed in Dispatch Styles.
In general, using multiple multiplicity results in improved overall application runtime performance only when the runtime cost of the following sequence of events is significantly less than performing the computation that occurs within the multiply-instantiated instances themselves:
-
Queuing tuples at parallel region boundaries.
-
Dispatching the tuples to their respective multiply-instantiated instances.
-
Re-scheduling processing of the tuples for separate processor scheduling opportunities.
-
Then moving the tuples between parallel regions.
These constraints suggest that the granularity of the work performed within a multiply-instantiated instance should be relatively large — usually much larger than the amount of work performed by a single operator or a small number of operators. Therefore, although the Multiplicity = multiple setting can be used with any operator that supports multiplicity, it is usually only used for Module References.
If you know that portions of your StreamBase application can run without dependencies on the other streaming data in your application, you may be able to improve the overall throughput by allowing those portions to run in their own parallel regions. Parallel regions are usually implemented as separate threads in the JVM running StreamBase Server, but do not think of parallel region and thread as exactly synonymous terms. For example, it is possible for more than one parallel region to execute, serially, in the same thread. It is also possible for separate scheduled executions of the same parallel region to occur in different threads. See Parallel Region Defined.
In StreamBase Studio, in the Properties View for most operators, the Concurrency tab includes an option to Run this component in a parallel region (which changes to Run each instance of this component in a parallel region when Multiplicity = multiple).
This option is available for most operators, except those that need to be processed sequentially. The option to run in a separate parallel region is not available for the Sequence operator, or for Query operators connected to Query Table data constructs. By contrast, the option is available for Query operators that are connected to JDBC Table data constructs.
Let's say you have two Module References for separate subsets of an application. Each Module Reference is set to run in its
own parallel region. In addition, when the StreamBase application runs, one additional region is created for the processing
of the rest of the application; that region is named main.
You can specify the parallel region option for an individual operator, which would then get its own parallel region. If the individual operator you mark to run in a separate region resides in a module referenced by a parent application, the operator does get its own region, but the other operators in the module run in the containing module's region. Instead, the best practice is to group a set of operators (and any data constructs they use) into a single module, make a Module Reference to that module, and then mark the Module Reference to run in its own thread. Do this only if the Module Reference can run concurrently without data dependencies on other components in your application.
Under heavy load, modules running in parallel regions may not be able to immediately process a tuple. In this case the tuple is queued in the parallel region until it can be processed later. If this queuing continues without bound, memory resources will also be exceeded and the performance of the application will be significantly impacted as the queue depth grows. To avoid this congestion, the maximum number of tuples to queue on a parallel region can be configured. When this queue depth is hit back-pressure is exerted preventing additional work from being queued in the parallel region. When back-pressure is in affect, the thread queuing the inbound tuple will block until the queue depth drops below the configured maximum value, releasing the back-pressure.
When back-pressure is exerted all locks are released to avoid holding locked resources that might prevent work from progressing.
For example, a parallel region as a multiplicity of four with a path of
default.SlowModule, the runtime will generate four paths:
-
default.SlowModule:0 -
default.SlowModule:1
-
default.SlowModule:2
-
default.SlowModule:3
Set the
streambase.runtime.stream-queue-max-tuples-<parallel-region-module-path>
property in the system:
jvmArgs =
[
"-Dstreambase.runtime.stream-queue-max-tuples-default.SlowModule.*=10"
"-Dstreambase.runtime.stream-queue-max-tuples-default.SlowModule%3A0=100"
]
The first example uses a regex to set 10 as the maximum number of tuples allowed to be
queued for all instances of default.SlowModule. The second example sets the
maximum number only for the first instance (default.SlowModule:0) and sets
the value to 100. The other instances will use the default of 0 (no limit).
Note
%3A is required since the property is represented as a URL, which
needs to escape the colon.
Multiplicity and the ability to run in a separate region are distinct and independently controllable properties of operators. When you enable both separate regions and multiple multiplicity, each instance runs in its own region. (The use of both multiple multiplicity and separate regions together was formerly known as data parallelism.)
You might use single multiplicity and separate regions when you only want to spin off some computation in a module to run asynchronously from the rest of your application's processing.
You might want to use multiple multiplicity and separate regions when you not only want some computation in a module to run asynchronously, but the module's design makes it possible to spin off more than one region and to divide the work across them arbitrarily, independent of the values of the incoming tuples. In this case, set the dispatch style of the input port on which tuples arrive to Round Robin.
Another scenario for using both multiple multiplicity and separate regions is where you not only want a module to process
asynchronously, but the module's design makes it possible to dispatch multiple instances using an expression that uses values
in the incoming tuple. For example, the incoming tuple might have an integer customerNumber field and the processing might involve a computationally expensive analysis of all the orders received from the identified
customer. In this case, set the dispatch style of the input port on which the tuple arrives to Numeric and set the number of instances to a number that reflects how much concurrent computation power you want to devote to the
analysis. (This number of multiple instances should not exceed the number of CPU cores available.)
As a guideline, suppose further that the analysis depends on the current temperature, such as for a local business that sells ice cream. In this case, the Module Reference could have another input port on which tuples arrive reporting the current temperature as it changes. For this input port, set the dispatch style to Broadcast because all the module instances require the same temperature information.
Using multiple regions can improve runtime performance on multiprocessor machines. However, using too many regions can actually hurt performance. And the inherent asynchrony that results from using multiple regions makes the behavior of your application harder to describe and predict.
Before you enable multiple multiplicity for a component, read this section and determine whether any of the following cautions applies to your StreamBase application.
For operators and modules that maintain state while the application is running, it is typically required that you use the Numeric dispatch style and an appropriate dispatch expression.
Aggregate, BSort, Gather, Join, Merge, and Query Tables are stateful components. Any component marked for multiple multiplicity will have multiple instances of any of these objects instantiated. For objects that maintain state, the state will be available only to the instance that it is part of.
Consider a Module Reference that specifies two multiple instances and separate parallel regions in an attempt to improve performance
on a dual-core machine. Suppose the referenced module contains a Query Table whose primary key is a stock symbol and whose
other column is the total number of shares traded in that stock, based on ticker information in incoming tuples. In this scenario,
it would be appropriate to use Numeric dispatch style and a hash of the symbol as the dispatch expression. Why? Consider what would happen if you instead used Round Robin dispatch style: some tuples with the same symbol, such as IBM, would be sent to one instance, while other tuples with the IBM symbol would be sent to the other instance. One instance's Query Table would have its IBM row updated with one subset of
the incoming tuples, while the other instance's Query Table would have its IBM row updated with a different subset of the
incoming tuples. Neither table would correctly contain the total number of shares traded.
Note that a Query operator's read all rows operation returns all the rows for the containing region, not all the rows from all regions.
Similar issues using other stateful objects means that modules that use them must be dispatched using the Numeric dispatch style.
The goal and need is not to have one instance per dispatch key value, but rather that all incoming tuples that generate the same dispatch key always go to the same instance. (Multiple dispatch key values might go to a single instance.)
Do not enable multiple multiplicity for modules that contain file-based or TCP-based embedded adapters. For example, you might inadvertently set up multiple instances of an adapter trying to simultaneously read from and write to the same file or port. Two CSV Writer adapters could not open the same file for writing simultaneously, which is what using multiple multiplicity for that adapter would try to do. (The name of the file is part of the adapter's configuration so it would be the same in all instances of the adapter.) To avoid this scenario, do not enable multiple multiplicity for modules that contain these types of embedded adapters.
By contrast, a TCP-based output embedded adapter, such as the Spotfire Streaming E-mail Sender Output Adapter, does work well with multiple multiplicity.