
Contents
![]() The Gather operator receives input from two or more streams and
concatenates tuples that share the key value. The Gather operator is often used when a tuple
needs to be split into multiple branches of an application, and then rejoined later on for
further processing.
The Gather operator receives input from two or more streams and
concatenates tuples that share the key value. The Gather operator is often used when a tuple
needs to be split into multiple branches of an application, and then rejoined later on for
further processing.
The Gather operator releases a new tuple, on a single output stream, that can be a function of any of the input tuple fields. By default, Gather buffers input tuples for each value of the key field until that value is seen on each of the input streams. Only then is the output tuple released. Matching tuples can arrive in any order (input need not be synchronized), and tuples are emitted in the order that they are fully matched. You can change the default behavior by setting a timeout interval.
Note
Avoid duplicate keys or use them with caution, because they can have unexpected results. If two or more tuples with duplicate keys are received on the same stream before the first is emitted, you have the option to discard either of them, or keep the first one and emit an error.
Also, keep in mind when designing Gather operations that unmatched input tuples remain buffered at run time. Use one of the timeout options to limit buffer sizes.
This topic describes how to set Gather operator properties in the Properties View, and traces the execution of a gather operation.
Name: Use this required field to specify or change the name of this instance of this component. The name must be unique within the current EventFlow module. The name can contain alphanumeric characters, underscores, and escaped special characters. Special characters can be escaped as described in Identifier Naming Rules. The first character must be alphabetic or an underscore.
Storage method: Specify settings for this operator with the same in heap and in transactional memory options described for the Annotations tab of the EventFlow Editor. The default setting is Inherit from containing module.
Enable Error Output Port: Select this checkbox to add an Error Port to this component. In the EventFlow canvas, the Error Port shows as a red output port, always the last port for the component. See Using Error Ports to learn about Error Ports.
Description: Optionally, enter text to briefly describe the purpose and function of the component. In the EventFlow Editor canvas, you can see the description by pressing Ctrl while the component's tooltip is displayed.
In the Gather Settings tab, shown below, specify the number of incoming streams that participate in the gather as the , and the field by which to gather as .
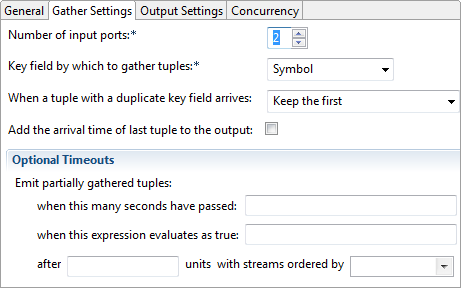
The Gather Key field can be any data type that can consistently order tuples and can serve as a key identifier. The timestamp data type is typically used. The timeout limits how long Gather continues to buffer tuples, and is measured in units appropriate for the specified field's data type. If you specify an int or double field, the timeout interval is measured in those units. If you specify a timestamp field, the timeout interval is measured in seconds.
You can control how the Gather operator handles duplicate key values by choosing an option from the dropdown menu :
Select the checkbox if you want downstream operators to have access to this information.
By default, the Gather operator buffers input tuples until the same key value is seen on all streams. Only then does it combine the matching tuples and clear them from its buffer. You can limit and control the extent of buffering by setting one or more of the timeout options under Emit partially gathered tuples:
-
When this many seconds have passed (enter a double or an int)
-
When this expression evaluates to true (enter a boolean expression)
-
After (enter an int count) units (the next value, a field name, must also be specified)
-
(select a field. The value for After must be specified)
-
When you specify a timeout interval, instead of waiting indefinitely until the key value has been seen on all the input streams, Gather first establishes the current time by listening for a tuple on each input port. It then waits until either the required gather conditions are satisfied, or until a timeout occurs, whichever happens first. A timeout occurs when a tuple arrives whose time (compared to the initial time established earlier) exceeds the specified timeout period. When the time is updated this way, the Gather operator emits a tuple. The missing input tuples' fields are set to null when the output expressions are evaluated.
If you enable timeout, you can also enable another option, Output arrival time of last tuple. This option adds a field-named last_time to the output schema. This field is populated at runtime with the latest time at which an input tuple was received corresponding
to that output tuple. The last_time field is always sorted across output tuples, so that it can reliably be passed to Aggregate operators. To ensure this sorted
condition, Gather keeps a full timeout interval's worth of data buffered at all times.
You can also specify a predicate expression to control timeout. When the expression evaluates to true, the operator emits partial results, even if the timeout interval you have specified has not yet elapsed. For example, if you are gathering from three streams and you want to emit when the one has data and either of the other inputs receives a null tuple, you could force emission with a predicate expression such as:
notnull(input1) && (notnull(input2) || notnull(input3))
Be aware that if no timeout options are specified, arriving tuples will continue to be buffered until a match occurs, which can increase latency and potentially exhaust memory.
The Output Settings tab allows you to specify the schema of the operator's output tuple. Output tuples are released when the Gather operator has seen a tuple with a specific key value on each of the streams or a timeout occurs, as described above.
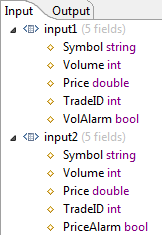
The Output Settings tab contains one Input n Fields grid for each input port specified on the Gather Settings tab, plus an Additional Expressions grid. Gather operators always have the Input 1 Fields and Input 2 Fields, corresponding to input ports 1 and 2.
Field grids and the Additional Expressions grid operate the same way that they do in the Output Settings tabs for the Map and Query operators. That is, the changes you specify in this tab are applied in top-down order in two ways: top to bottom in the order of grids in the tab, and top to bottom in the order of field expressions in each grid. That is, the output tuple is assembled in the following way:
-
Fields in the incoming tuple on port 1, if any are specified.
-
Fields in the incoming tuple on port 2, if any are specified.
-
Fields in the incoming tuple on ports 3 through n, if any are specified.
-
Any additions, subtractions, or reorderings for input tuple fields in grid and port number order.
-
Any additions, subtractions, or reorderings for any of the above fields as determined by expressions in the Additional Expressions grid.
Use the field grids as described for the Map operator in Using Field Grids. Differences for the Gather operator are:
-
When an Input
nFields grid is open, the Prefix field is not blank, but is filled in for you withinput1_for Input 1 Fields,input2_for Input 2 Fields, and so on. You can change the prefix or remove it, as your application requires. It is a best practice to leave the default prefixes in place, or use similar prefixes, to help distinguish same-named fields on incoming streams. -
When referencing fields in expression cells, use
input1.as a qualifier for fields in input port 1's tuple, useinput2.to qualify fields in input port 2's tuple, and so on.
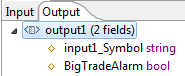
In the following figure, the Gather operator's Output Settings tab specifies the following structure for the schema of the tuple to be emitted from the operator:
-
From input port 1, select only the
Symbolfield, and prefix its name withinput1_. -
From input port 2, select no fields.
-
Append an additional boolean field-named
BigTradeAlarm.
 |
The effect of settings is reflected in the Input Streams and Output Streams sub-tabs on the right side of the Properties view:
 |
 |
Use the Concurrency tab to specify parallel regions for this instance of this component, or multiplicity options, or both. The Concurrency tab settings are described in Concurrency Options, and dispatch styles are described in Dispatch Styles.
Caution
Concurrency settings are not suitable for every application, and using these settings requires a thorough analysis of your application. For details, see Execution Order and Concurrency, which includes important guidelines for using the concurrency options.
Consider a simple application with a Gather operator that has two inputs. Both input streams receive tuples containing a stock symbol and a volume of shares. The inputs can be asynchronous: tuples may arrive at different rates on each stream. Using the stock symbol field as the key, the Gather operator sums the volume of matching stocks from the two input streams, and emits a tuple listing the stock's symbol and its summed volume. The timeout option is not enabled. Let us trace a series of tuples flowing into the Gather operator in this application.
In the diagrams below, each step depicts a new tuple being enqueued to the Gather operator, and any output that results. The contents of the two operator buffers are shown after each tuple arrives and after any tuples are released.
-
A tuple enters the Gather operator on the first input port and is stored in the buffer:

-
A second tuple enters on the first port. Nothing is emitted by the Gather operator because both buffered tuples entered on the same input port, and because the symbols do not match:

-
A tuple enters on the second port. This time, the conditions for the gather operation are met: the key field is matched by tuples on both input ports. In the gather operation, the volumes of the AAPL tuples are summed, the result is emitted in an output tuple, and the matching tuples are released from the buffer.

-
This step introduces the problem that can be caused by duplicate keys on the same stream. The new tuple's key field (IBM) matches the key field of an existing tuple on the same port. As you should expect, there is no output because the match did not occur on both ports. But notice in the figure that the new tuple replaces the existing tuple. In the next step, we will see how this affects the Gather result.

-
A tuple arriving on the second port matches a tuple on the first port, and Gather releases the result. Notice that the value of the output tuple is the sum of the last two key field values (289 and 350). The earlier IBM value of 300 will not be used: it is effectively lost in this Gather operation.

To summarize this example:
-
No output is emitted until step 3, when the same key has been seen on both input ports. The output is the sum of the AAPL volumes that arrived on the Gather operator's first and second input ports.
-
Steps 4 and 5 show the potential side effects of duplicate keys on the same stream.
This example traces the execution of a Gather operator that has the timeout option set. The input schema has three fields: a stock symbol, its price, and its timestamp. The Gather operator has two input ports. Each accepts stocks with different values (this might be accomplished by using a Filter operator upstream from the Gather operator). The first input port receives Stocks with values equal to or greater than 200. The second port contains stocks worth less than 200. Like the first example, this operation gathers on the symbol field. Timeout is enabled with a timeout interval of 10 seconds, ordered by the timestamp field. Notice that the Output arrival time of last tuple option is not selected.
As in the first example, each step shows a new tuple being enqueued to the Gather operator, and any output that results. In addition, these figures have an additional timestamp field at the end.
-
A tuple enters the Gather operator on the second input port and is stored in the buffer. This arrival establishes the start time on the second port:

-
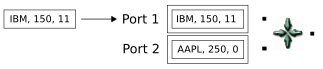
A tuple enters the Gather operator on the first input port and is stored in the buffer. Notice that this tuple arrives 11 seconds after the first tuple. Thus, the specified timeout interval has elapsed without a gather occurring:
-
The third tuple arrives on the second port, and the Gather operator emits two output tuples:

Why are two tuples emitted?
-
The input tuple on Port 1 triggers a gather because its key field (IBM) matches the key field on a tuple in the Port 2 buffer.
-
When the gather occurs, the timeout interval has already elapsed (the time values of the first and second tuples is greater than 10). This is why a second tuple is emitted with the missing gather fields set to null.
If the third input had not matched on the key field, only the timeout tuple with the null fields would have been emitted.
-
This example traces the execution of a Gather operator that has both the timeout and Output arrival time of last tuple options set. With these options, we are interested not only in the gather result, but also in the arrival time of the last tuple. Otherwise, the application in this example is identical to the one in Example 2: Gather with Timeout. Each step of this example shows a new tuple being enqueued to the Gather operator, and any output that results.
-
A tuple enters the Gather operator on the first input port and is stored in the buffer. This tuple establishes the start time on the first port:

-
A tuple enters the Gather operator on the first input port and is stored in the buffer. Notice that this tuple meets the normal criteria for a gather to occur: the symbols are matched on both input ports, and both tuples arrived within the timeout interval.
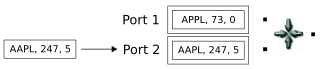
Why is no tuple emitted? The
last_timevalue cannot be established until the timeout period expires, and the time is then updated on all of the Gather operator's input ports. So at this point, more input must arrive before a gather operation can occur. -
A third tuple arrives on the second port. Notice that the elapsed time since the last gather tuple (15 seconds) exceeds the timeout interval. This establishes the elapsed time on the second port for the purposes of the timeout:

-
When the fourth tuple arrives on the first port, Gather is able to establish the elapsed time since the last gather event. The operator emits a tuple with the gather result and the time value for the second tuple, which was the last tuple in the gather operation:
