
Contents
This page describes the timestamp related options of the Feed Simulations Editor. See Using the Feed Simulation Editor for more on the Editor.
The feed simulation timestamp features described on this page may require you to specify a timestamp format pattern that determines the interpretation of a date and time specified in string form. StreamBase applies the timestamp format pattern to the time and date strings, and substitutes a StreamBase timestamp data type.
The timestamp format pattern uses the time formats of the java.text.SimpleDateFormat class described in the Oracle Java Platform SE reference documentation. Once you have determined the timestamp format pattern that describes your data file's date and time information, type that
format pattern string into the Timestamp format field of the Data File Options dialog.
The following table shows some simple examples of timestamp format patterns. Study the SimpleDateFormat reference page to understand how to describe more complex examples.
| String Data in the CSV or Text Data File | Timestamp Format Pattern |
|---|---|
| 12/25/09 | mm/dd/yy |
| 25-Dec-2009 | dd-MMM-yyyy |
| 11:27 AM | h:mm a |
| 14:26:00 | HH:mm:ss |
| 09:47:26.374-0500 | HH:mm:ss.SSSZ |
| 2009-12-25 13:26:02 | yyyy-MM-dd HH:mm:ss |
When using a data file or database query as input for your feed simulation, you can specify one input column as the source of a relative timestamp to use in timing the simulation. If you are using a captured feed as input, and the original feed includes timestamp values, you can use this feature to run your feed simulation with the exact same pace of sending tuples as used by the original feed.
When using a JDBC database query as the timestamp column, the data type of the specified timestamp column must be StreamBase timestamp or double. When using a column of a data file as the timestamp column, the data type must be either double or the string representation of a timestamp.
When using a column of type double, the numbers represent seconds. When using a string representation of a timestamp, you must also use the Timestamp format field in the Data File Options dialog as described in Specifying Timestamp Formats.
When the feed simulation is run, tuples are sent on the schedule specified by the time difference in seconds between each successive timestamp. That is, StreamBase ignores the absolute time and date in the timestamp value, and instead calculates the relative amount of time between the timestamp in each incoming tuple.
For example, we might have an input CSV file that starts with the following lines:
BA,51.25,09/27/08 16:20:30,100.0 DEAR,25.43,09/27/08 16:20:45,102.0 EPIC,142.85,09/27/08 16:20:50,105.0 FUL,15.76,09/27/08 16:21:00,105.5 GE,25.151,09/27/08 16:21:05,106.0
(This is the same file used as an example in the picture of the Data File Options dialog.)
In this example input file, we can designate either column 3 or 4 to be a source of relative timestamps:
-
To use column 3 as the timing source, designate column 3 in the Timestamp from column option, and set the option to start counting from the first value read. You must also specify the string
mm/dd/yy HH:mm:ssas the format specifier for the timestamp strings in column 3. In this case, the feed simulator sends the first tuple immediately on startup, then sends the next few tuples on the following schedule:First tuple sent On startup of the feed simulation Second tuple sent 15 seconds later 16:20:45 minus 16:20:30 = 15 seconds Third tuple sent 5 seconds later 16:20:50 minus 16:20:45 = 5 seconds Fourth tuple sent 10 seconds later 16:21:00 minus 16:20:50 = 10 seconds Fifth tuple sent 5 seconds later 16:21:05 minus 16:20:00 = 5 seconds And so on ... ... -
To use column 4 as the timing source, designate column 4 in the Timestamp from column option, and set the option to start counting from the first value read. In this case, the feed simulator sends tuples according to the following schedule:
First tuple sent On startup of the feed simulation Second tuple sent 2 seconds later 102 minus 100 seconds = 2 seconds Third tuple sent 3 seconds later 105 minus 102 seconds = 3 seconds Fourth tuple sent 1/2 second later 105.5 minus 105.0 seconds = 0.5 seconds Fifth tuple sent 1/2 second later 106.0 minus 105.5 seconds = 0.5 seconds And so on ... ...
It is possible to use the Timestamp from column feature even for streams with an empty schema. An input stream might have an empty schema, for example, when used as input to a Query operator configured for Read operations. In this case, sending an no-fields tuple to the stream triggers the Query's Read operation.
In this case, any data file used to feed tuples to such a stream cannot have any fields. So why use a data file at all in this case? The data file for an empty schema stream can contain a single column of timestamp or double values that you use with the Timestamp from column feature described in the previous section. In this way, your feed simulation can trigger a Query Read operation on the schedule defined by the differences between values in the timestamp column.
The Timestamp Builder allows you to build a single timestamp from a combination of one or more data file columns plus optional text strings. Use the Timestamp Builder field in the Data File Options dialog when the incoming data in the CSV or text file has components of a timestamp in different columns. For example, in a CSV file, the date of an event might be in column 3 while the time the event occurred might be in column 5.
Follow these steps to use the Timestamp Builder:
-
In the Data File Options dialog, fill in the Timestamp format field with a timestamp format pattern that describes the data found in two or more columns. See Specifying Timestamp Formats.
For example, in the figure below, the CSV file has the date in column 3 in the form month/day/year and the time in column 5 in the form hours:minutes, counting hours from 0 to 23. Therefore, you would enter the following timestamp format pattern:
MM/dd/yyyy HH:mm. -
In the Timestamp builder field, enter the column numbers of the CSV file columns that contain your date components, with each column number in braces, in the same order as described in the Timestamp format field. For example, for the date in column 3 and the time in column 5, enter
{3} {5}.Tip
As you enter your Timestamp builder string, StreamBase interactively attempts to interpret the specified data as a timestamp as described in the Timestamp format field, and shows failures in the top portion of the dialog. Use this as a guide to help you enter a valid Timestamp builder string that is interpreted without errors:
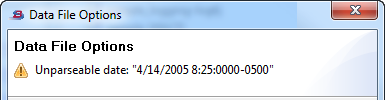
-
Determine which field in the input stream contains the timestamp data. (In the figure below, this is the
datefield.) In the Map to file column for that field in the Column mapping table, select Timestamp builder from the dropdown list. This tells StreamBase that the complete timestamp is to be generated from more than one column, as described in the Timestamp builder field.
The following figure illustrates the use of the Timestamp Builder feature.
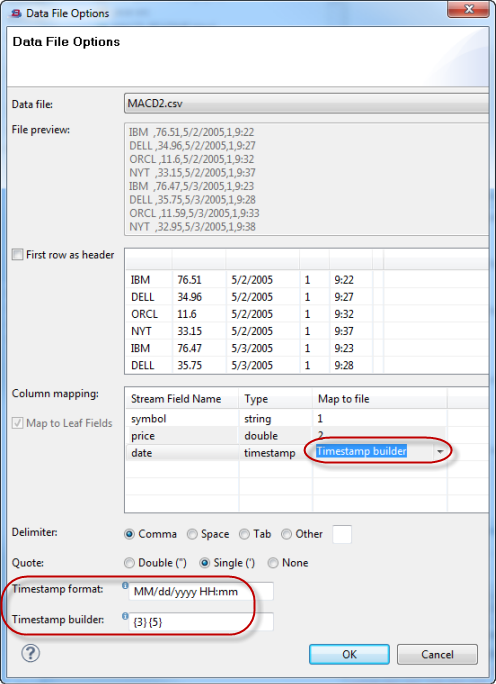 |
Your Timestamp builder string can also contain static strings to fill in portions of the date or time fields that will be interpreted the same for all generated timestamps. These strings must be accounted for in the timestamp format pattern in the Timestamp format field.
For example, your CSV file might have the date in column 1 and the hours, minutes, and seconds each in separate columns starting
with column 4. Let's say your Timestamp format field is MM/dd/yyyy HH:mm:ss, which specifies colons between the portions of the time. In this case, add static colons to your Timestamp builder string between the column designators for the time components: {1} {4}:{5}:{6}.
You can use static strings in your Timestamp builder string for many purposes. For example, consider the CSV file illustrated in the figure above, but with a Timestamp format string that specifies hours, minutes, and seconds (MM/dd/yyyy HH:mm:ss), and a Timestamp builder string that uses static numbers in the hours portion of the time string: {3} 00:{5}. This would force column 5 to be interpreted as minutes and seconds instead of hours and minutes. You might do this in conjunction
with the Timestamp from column feature to replay a feed simulation with the same relative timings as the originally collected CSV file, but significantly
faster.
The synchronized timestamp group feature relies on and extends the Timestamp from column feature described in Using the Timestamp from Column Feature above. Make sure you read and thoroughly understand that section before attempting to use the Synchronized Timestamp Group feature.
The synchronized timestamp group feature lets you designate the currently selected input stream as a member of a group of streams in the current feed simulation file for which StreamBase coordinates delivery of tuples in timestamp order. Use this feature on two or more streams in the same feed simulation file to have the tuples on each stream arrive at StreamBase Server sorted in timestamp order.
For example, you might have two CSV files from a market data vendor, one containing quote information, the other containing trade information. Each CSV file has a timestamp field for each tuple. Your feed simulation can read the two CSV files as Data File sources onto two different input streams, with the tuples on the two streams coordinated in timestamp order.
The check box that enables this feature is dimmed and unavailable unless:
-
The currently selected stream in the Simulation Streams section specifies a Data File or JDBC generation method.
-
You enabled the Timestamp from column feature and specified a column in the input schema to use as a source of timestamp information.
When you select the Include in synchronized timestamp group check box, the using ... start time control in the Timestamp from column line automatically changes to first value read, and dims out to prevent you from changing that setting. The synchronized timestamp group feature always uses the first value of the associated data file or JDBC table as the starting point.
The synchronized timestamp group feature does not expect the data sources feeding two input streams to have an equal number of tuples. This feature is not an attempt to force two or more input streams to line up tuple for tuple.
Instead, this feature's purpose is to compare the timestamps of each tuple on all streams in the synchronized group, and to allow tuples onto each stream in the correct relative order. This feature guarantees that all streams in the synchronization group receive their incoming tuples in monotonically increasing order, and in time order relative to wall clock time.
The streams in the synchronized timestamp group do not need to have the same schema, or even similar schemas. The only requirement is that each stream's schema contains a field of monotonically increasing timestamp values (or contains numbers or strings that can be interpreted as timestamp values).
For example, consider the following two CSV data files, where the first column contains integer values representing the number
of seconds elapsed since the start of the trading day. The first file, quotes.csv, serves as the data source for input stream InQuotes, and contains:
1000,IBM,115.67 1002,DELL,15.24 1003,MSFT,25.89 1006,IBM,116.10 1008,ORCL,20.89 1010,DELL,15.59 ...
The second file, trades.csv, serves as the data source for input stream InTrades. It contains:
1005,115.54,A8934T34,IBM 1008,15.88,B2399W05,DELL ...
You have a feed simulation file where both InQuotes and InTrades are listed in the Simulation Streams section. In the Processing Options section:
-
Select
InQuotesandInTradesin turn, and set each stream for Timestamp from column1. -
For each stream, check the Include in synchronized timestamp group check box.
Now when you run your application and send it your feed simulation, the two streams receive the tuples shown in the following table, in the order shown.
| Relative time order of the feed simulation | InQuotes Stream receives | InTrades Stream receives |
|---|---|---|
| start of feed simulation | 1000,IBM,115.67 | |
| +2 seconds | 1002,DELL,15.24 | |
| +1 second | 1003,MSFT,25.89 | |
| +2 seconds | 1005,115.54,A8934T34,IBM | |
| +1 second | 1006,IBM,116.10 | |
| +2 seconds | 1008,ORCL,20.89 | 1008,15.88,B2399W05,DELL |
| +2 seconds | 1010,DELL,15.59 |
For the case where both streams had a transaction at timestamp 1008, the tuple might arrive on the two streams in either order. There is no guarantee that any stream in a group receives same-timestamp tuples in any predictable order. The only guarantee is that each stream receives all its tuples in order.
Feed simulations that use the synchronized timestamp group feature cannot use client buffering. This means that:
-
When running such a feed simulation in Studio, the default client buffering normally used is automatically disabled.
-
When running such a feed simulation on the command line with sbfeedsim, you must use the option
-b 0to disable all client buffering. For such feed simulations, do not use the-boption with any other argument, and do not run sbfeedsim without-b 0.
As a consequence of disabling client buffering, feed simulations with a synchronized timestamp group may run slower than feed simulations without the group feature.
Client buffering is not the same as tuple buffering. The default tuple buffer of 40,000 is still used, both in Studio and with sbfeedsim. You are free to modify the tuple buffering number, and to use the prefill and prefill and loop options in conjunction with a synchronized timestamp group.