Contents
A capture field is an opaque datatype. The name "capture" describes its role, which is to encapsulate zero or more fields in an input stream or imported table to make them opaque to the module receiving them. Declaring a capture field on an input stream or placeholder table avoids interpreting the additional fields as they pass through the module. Names of fields inside the capture will not conflict with names inside the module. Upon sending an event from the module back to the original scope where the fields were defined (i.e. the containing module) the contents of the capture field are expanded back to the original field names, types, and values. Note that while name conflicts inside the module were not an issue, field names in the output message cannot collide with names in the expanded capture. Should such duplicate names exist when a stream exits a module, a typechecking error results.
Capture fields shield a module's logic from input schema fields that are irrelevant to the module's operation. With them, you can create service and library modules that can be broadly and safely reused.
You can configure modules designated as hygienic to have a capture field on their input stream schemas and table schemas. If a stream connected to a Module Reference contains additional fields not specified in the module's input schema, these additional fields are encapsulated in the capture field, and are then passed around inside the module as an opaque blob. In output streams issuing from the module, the captured fields are restored to have their original field names and data types.
Capture fields are only active in hygienic modules, which requires strict compliance of the Module Reference's schema with the module's schema. Under these conditions, the capture field's actions occur at the module boundaries. When a tuple enters the stream of a module with a capture field, the capture field gathers the incoming fields that do not comply with the module's schema into the blob. When the tuple exits the module, the non-compliant fields are reconstructed.
Typechecking does not prevent you from adding a field of type capture to a non-hygienic module, but such a field does not have the properties of a capture field, and does not operate at the module boundaries. When you designate this non-hygienic module as hygienic, the capture field becomes active.
Capture fields serve several roles in StreamBase:
-
A capture field in a module's input schema allows you to combine the strict typechecking of hygienic modules with the flexibility of non-hygienic modules.
-
A capture field in a Query Table's schema allows the same table definition to be re-used in different ways in copies of a module.
-
When combined with the parent schemas feature, you can create abstract modules that can flexibly handle similar concrete uses with different input schemas.
-
You can create custom Java operators that are able to look into the contents of capture fields.
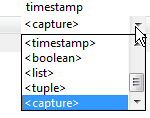
In EventFlow modules, create a capture field by selecting <capture> from the drop-down list of data types in the
Type column of any Properties view Edit Schema tab.
|
Capture fields have both a field name and a capture data type that you name. By
default, the data type name type is entered for you.
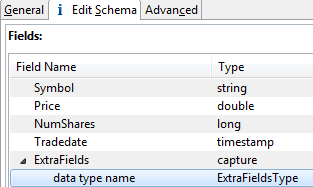
Edit this name to provide a type name that matches the field name in some way. In the
following example, the capture field's name is ExtraFields and its data type name is ExtraFieldsType:
|
The field name and data type name for capture fields are arbitrary, and you can use any names that meet the identifier naming rules. TIBCO recommends tying the two names together as shown here so that you can more easily track a capture data type back to its originating capture field.
Each tuple can have exactly one capture field per tuple level. One capture field can
be defined in the top-level tuple of a schema, and one capture field in each tuple
field. The data type name for each capture field helps keep track of which capture
fields to expand at which levels on exit from the module. Also, since a module can
have multiple input streams, and each stream can have its own independent capture
field, the data type name distinguishes the capture fields from different streams.
For example, a module might have capture fields both named indata in the schemas of two input streams. Those capture fields are
distinguished by their capture names, such as indata(IS1) and indata(IS2).
The data type name for a capture field is analogous to the name of a named schema. Remember that StreamBase automatically creates a constructor function from the name you assign to named schemas so that the name of a named schema appears in the Type drop-down list as a new data type. Similarly, the data type name of capture fields is used as a parameter to tie together the definition of a capture field in a module with a use of the same capture field elsewhere in the same module. For example, a module that includes a Query Table might have a capture field with the same name and data type in both its input stream and its Query Table's schema:
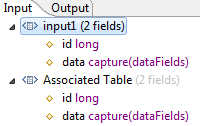
Capture fields show in schema listings in the form fieldname
capture(datatype-name)
Capture fields show in tooltips and in expressions with the @ sign before the data type name:

|
To create a null capture field, use the @ sign with data type name and empty
parentheses: @dataFields()
The simplest use for capture fields is to give hygienic modules the flexibility to accept fields on its input streams that are not defined in the module. Hygienic modules are strict: the schema of the Module Reference must exactly match the schema defined for the module's input streams, and this is enforced with typechecking. By contrast, a non-hygienic module's input schemas are overridden by the Module Reference's schemas, as long as the schemas are compatible enough to allow the module to perform its processing. See Hygienic Modules to understand the difference between hygienic and non-hygienic modules.
When you use a capture field with a hygienic module, you restore much of the flexibility of non-hygienic modules, but without giving up the advantages of strict typechecking.
Let's say you have a hygienic module named Calcit that returns a calculation based on an accumulated aggregate of values. The input stream for this module specifies three fields in its schema, plus one capture field. You can create a Module Reference that sends in a tuple with 20 fields, as long as three of the 20 fields have the same field names and the same or coercible data types as the input schema of Calcit. The other 17 fields are set aside by the capture field in a blob during Calcit's processing, and are reconstructed and restored on the way out. The module returns all 20 incoming fields, plus the results of its calculation.
When you include a capture field in the schema definition of a Query Table, that table becomes an abstract template that can accept different fields and data types in place of the capture field. Of course, this does not mean that a single Query Table can accept different schemas; in operation, a Query Table can have exactly one schema. It means that an abstract Query Table in a module can be used one way when referenced by module A, and used another way when a copy of the same, unchanged module is referenced by module B.
For example, a Query Table configured to hold addresses could be specified with a schema like the following:
| Field name | Data Type | Data Type Name |
|---|---|---|
| firstname_prenom | string | — |
| family_name | string | — |
| street_address | string | — |
| city | string | — |
| locale | capture | localetype |
When the module containing this table is used to store US addresses, the Module Reference in the outer module uses the following schema:
| Field name | Data Type |
|---|---|
| firstname_prenom | string |
| family_name | string |
| street_address | string |
| city | string |
| state | string |
| zip | long |
The schema of the Query Table for this instance of the module is the schema of the
Module Reference, where the state and zip fields override the placeholder locale field.
When the same module containing this table is used in a different outer module to store Canadian addresses, that Module Reference uses the following schema:
| Field name | Data Type |
|---|---|
| firstname_prenom | string |
| family_name | string |
| street_address | string |
| city | string |
| province | string |
| postalcode | string |
In this copy of the module, the province and
postalcode fields override the placeholder locale field of the template Query Table.
See the Capture Fields for Generic Data Store Sample sample for a working example of using capture fields with a Query Table.
The real power of capture fields is seen when combined with the parent schemas feature described in Using Parent Schemas.
When you specify a parent schema as the basis of a new schema, you can override any field in the parent schema by inserting a locally defined field with the exact same name and the same or a coercible data type. If the parent schema field you override is a capture field, you can insert fields with different names and data types in different copies of the same module. This allows you to make template abstract modules that perform a similar task for similar but not identical input types.
For example, an abstract module could be made that routes orders for trades of different financial instruments. Then, in one copy of this module, the Module Reference sends in tuples with a schema that makes the module an order router for FX trades. In another copy of the identical, unchanged module, a different Module Reference sends in tuples with a schema that makes the module an order router for Equities trades, or Bond trades.
This subject is best understood by studying the Capture Fields and Parent
Schemas Sample, especially the schema definitions in the SharedSchemas.sbint interface file. This sample places a capture
field named placeholder as the only field in a baseline
named schema named AbstractInstrument:
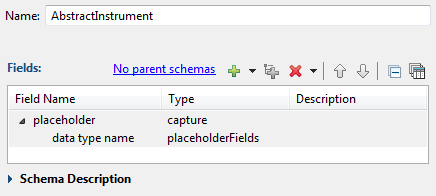
|
It then uses that named schema as a tuple field in the baseline AbstractOrders schema:
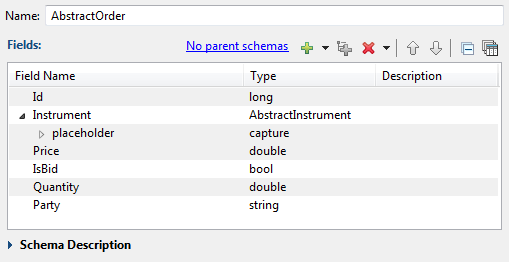
|
The sample then uses the AbstractOrder schema for the
input stream and Query Table in the OrderMatcher.sbapp
module.
To make schemas for the Module Reference for an Equities version of the Order Matcher
module, the sample starts by defining an EquitiesInstrument named schema that uses AbstractInstrument as its parent schema and adds the field specific
to Equities trading:
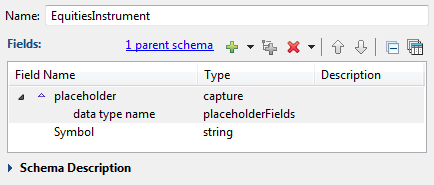
|
To complete the picture, the sample creates the schema for the Module Reference that
will override the abstract schema of the module. This schema uses AbstractOrder as its parent, and overrides the one capture field in
the parent with a local definition. Thus, the EquitiesInstrument named schema overrides the AbstractInstrument named schema because it uses the exact same field
name, Instrument:
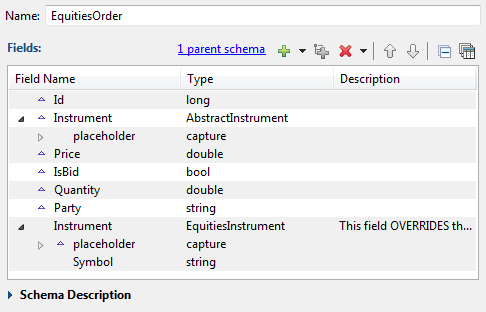
|
To re-use the Order Matcher module for FX trading, the sample creates the
FXOrder named schema that also uses AbstractOrder as its parent, then overrides the capture field with a
different named schema, FXInstrument:
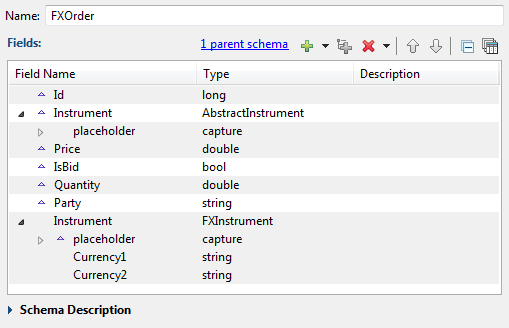
|
StreamBase includes two samples that illustrate different aspects of using capture fields:
-
The Capture Fields for Generic Data Store sample demonstrates how to use a capture field in the schema of a Query Table to make that table reusable in different copies of its containing module. Each instance of the table holds key-value data with different value data types for different instances. See Capture Fields for Generic Data Store Sample.
-
The Capture Fields and Parent Schemas sample demonstrates how to use capture fields in conjunction with parent schemas to create a reusable module that can match orders for FX trading in one instance and can match orders for Equities trading in another copy of the identical, unchanged module. The module uses abstract schemas for its input stream and Query Table that become concrete schemas in actual use. See Capture Fields and Parent Schemas Sample.