Contents
Important
The Materialized Window data construct remains available in StreamBase, but its use is discouraged.
A Materialized Window is a managed view of tuples passing through an input stream. The view can be based on a fixed number of tuples, a time interval, or a field value. It can also be partitioned into multiple windows. You can then directly query the data using one or more read-only Query operators.
A Materialized Window uses the most recently arrived tuple as the anchor point for interpreting dimension specifications. From the most recently arrived tuple, the Materialized Window examines previously stored tuples to determine if they fall within the specified dimension.
With tuple-based Materialized Windows, the window is configured to maintain a fixed number of tuples.
When a query is executed against the Materialized Window, the window identifies the most recently stored tuple and tests it
and the preceding n-1 tuples against the selection criteria. The query retrieves from the Materialized Window a collection of tuples, selected
from the most recently stored n tuples, which meet the selection criteria.
The number of tuples contained in the collection cannot be larger than n and, depending on the selection criteria, it is possible that the collection could be empty.
With time-based Materialized Windows, the window is configured to store tuples that arrive over a specified duration of time.
When a query is executed against the Materialized Window, the window determines the arrival time of the most recently stored
tuple and tests it and all tuples that arrived during the preceding s seconds against the selection criteria. The query retrieves from the Materialized Window a collection of tuples, selected
from the most recently arrived tuple and the tuples arriving during the preceding s seconds, which meet the selection criteria.
The number of tuples contained in the collection cannot be predicted from the configuration of the Materialized Window since
it is unknown how many tuples will arrive during the s second period. Depending on the selection criteria, it is possible that the collection could be empty.
With field-based Materialized Windows, the window is configured to store tuples whose value in a specified field falls within a certain range. To use this approach, the values in the specified field must be ordered such that they increase with each arriving tuple. While the tuple field may be of type integer or double, the range is of type double, which is the type used by the Materialized Window in evaluating its dimension.
When a query is executed against the Materialized Window, the window determines a value v in the specified field for the most recently stored tuple and tests previously arrived tuples whose field values are greater
than r-v against the select criteria. The query retrieves from the Materialized Window a collection of tuples, selected from the tuples
whose field value was within the specified range, which meet the selection criteria.
For example, if tuples with the following field values were submitted to the Materialized Window: 10, 11, 12, 13, 14, 15, and 16, and the specified range is 5.0, then the only tuples that could be included in the collection would have field values 12, 13, 14, 15, and 16. If the range were set to 5.1, then the tuple with field value 11 would also be evaluated for inclusion in the collection.
The number of tuples contained in the collection cannot be predicted from the configuration of the Materialized Window since it is unknown how many tuples will fall within the target range. Depending on the selection criteria it is possible that the collection could be empty.
The rest of this topic describes how to use a Materialized Window in an EventFlow application. (To use Materialized Windows with a StreamSQL application, see CREATE MATERIALIZED WINDOW Statement in the StreamSQL Guide.)
In the EventFlow application, an input stream feeds a Materialized Window data construct, which in turn is connected to one or more Query operators. Each Query operator reads the data in the Materialized Window and can pass through or manipulate the data in different ways, merging the result with tuples from its own input stream.
Note that a Materialized Window can be associated with multiple Query operators, but each Query operator can be associated only with one Materialized Window.
To use a Materialized Window in an EventFlow application:
-
Drag a Materialized Window icon from the Palette view to your canvas, creating a new data construct.
-
Open the Properties view of your Materialized Window data construct.
-
Name the component by editing the Properties: General Tab.
-
Choose the window type by editing the Properties: Window Settings Tab.
-
Optionally partition the data by editing the Properties: Secondary Indices Tab.
-
Optionally provide secondary indexes for faster searching by editing the Properties: Secondary Indices Tab.
-
Create the Query operator or operators that will be associated with the Materialized Window. For each one, drag a Query Table icon from the Palette view to the canvas.
-
Connect the Query operator or operators to the Materialized Window data construct.
-
Edit each Query operator's properties as described in Using the Query Operator.
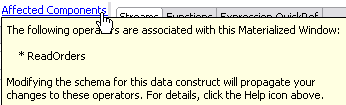
At the top of the Properties view for a Materialized Window data construct, there is an Affected Components link. Click this link to display a pop-up window that lists the Query operators in the current module that are associated with the selected Materialized Window. Click anywhere outside the pop-up to close the pop-up.
The following example shows an Affected Components pop-up window for the LastOrders Materialized Window in the MaterializedWindow.sbapp sample, which is a member of the Operator Samples group.
 |
Name: Use this required field to specify or change the name of this instance of this component, which must be unique in the current EventFlow module. The name must contain only alphabetic characters, numbers, and underscores, and no hyphens or other special characters. The first character must be alphabetic or an underscore.
Description: Optionally enter text to briefly describe the component's purpose and function. In the EventFlow canvas, you can see the description by pressing Ctrl while the component's tooltip is displayed.
In the Window Settings tab:
-
Choose the window Type and specify its boundary value in the Size field:
-
Tuple: The window (or each partition in the window) will contain a fixed number of tuples. (For more information on partitions, see Properties: Partitions Options Tab.)
In the Size field, enter an integer number of tuples. The window will contain up to the specified number of tuples. When an arriving tuple would cause the window to exceed that size, the window closes. A new window opens with the arriving tuple as its first member.
-
Time: The window will include tuples that arrive during a specified time.
In the Size field, enter a time interval in seconds; you can use a fractional value to specify milliseconds. After the specified interval, the next arriving tuple causes the window to close. A new window opens with the arriving tuple as its first member.
-
Field: The window will include tuples whose key fields have values within a certain range of each other. Note that this option is only available if the input stream schema contains at least one field of numeric data type: int, long, double, or timestamp (where the units are interval timestamps expressed in seconds, with fractional milliseconds).
Click the drop-down control and choose the incoming field on which you want to base the window. In the Size field, specify the size of the range of values.
As each tuple arrives, its key field is compared to the same field in existing tuples. If the values of all the key fields are within the specified range, the tuple is added to the Materialized Window. If the new tuple causes the values in all the key fields to exceed the range, the new tuple is added but one or more existing tuples are flushed from the window, so that the key fields of the remaining tuples do not exceed the range.
For example, suppose you define a Materialized window. For Field you enter
TradeID, and the Size is20:-
Two tuples arrive with
TradeIDvalues of 5 and 15. At this point the window includes both tuples because their key field values are within 20 of each other. -
Next, suppose a tuple arrives whose
TradeIDfield is 25. The window stores the latest tuple. Now the key value 5 is out of the specified range, so its tuple is flushed. The remaining tuples haveTradeIDof 15 and 25, which is just within the range. -
Finally, a tuple arrives with a
TradeIDvalue of 57. Now, after storing this tuple, the window flushes all the others, because none of their key fields are within the specified range from the new tuple.
-
-
-
Specify the Storage type: either
In memoryorOn disk.The On disk option is only available if your StreamBase license enables it.
When using this option, you can you can accept the default location for the Materialized Windows data or you can designate a data directory, using the rules described for disk-based Query Tables in Setup For On-Disk Query Tables.
-
Specify the Access Level:
- Private
-
Restricts this Materialized Window's visibility to the module that defines it. This is the default setting.
- Shared
-
Marks this Materialized Window in the current module as accessible to a Query Operator in a separate module.
When a Module Reference refers to a module that contains a Shared Materialized Windows, its icon displays a gray data port on its top edge, similar to the data port on top of a Materialized Windows icon. You can connect a Query operator in the separate module to the shared window by means of this data port.
Important
StreamBase does not support exporting a Materialized Window from a module marked with the Run in a parallel region concurrency option. See Concurrency Options for details.
For tuple-based Materialized Windows only, you have the option of creating partitions based on key fields. A partition is
created for each instance of the field that you specify. Each partition can have up to the number of tuples specified in the
Size field specified in the Window Settings tab.
For example, if you partition based on a field named Symbol, a partition is created for each value of Symbol that arrives on the input stream. Thus, you might have separate partitions IBM, CTXS, and INTC. If the window size was set
to 20, each partition can contain up to 20 tuples.
Partitions are optional. Without partitions, all tuples in the window are treated as a single group. Note that you cannot
set partitions (and the Partition Options tab is not usable) if you set the Time or Field type in the Window Settings tab.
To specify a partition, use the controls to move one or more fields from the Available Fields column to the Selected Fields column. If you add multiple fields, the partitions, are based on combinations of those fields. For example, if you add two
fields, ID and Class, a partition is created for each combination of ID and Class that arrives on the input stream.
A Materialized Window has a primary index that is created and managed automatically by StreamBase. You can optionally specify one or more secondary indices in the Secondary Indices tab, specifying key fields to use when looking up values. Note that if you have partitioned the Materialized Window, indexing occurs within each partition.
Secondary fields can speed up performance during queries. For example, if you have defined a partition, you can also create a secondary index based on the partition field. Then, later when you configure a Query operator, you can set your query to read the secondary index instead of all the rows. To define a secondary index:
-
Click to display the Edit Secondary Index dialog.
-
In the Available Fields list, double-click each field that you want to add to the index.
-
Click the button.
-
In the Available Fields list, double-click each field that you want to add to the index. (Alternatively, use the arrow buttons.)
You can also choose how keys are indexed for table read operations by using the Index Type control:
- Ordered, with ranges (btree)
-
Keys are sorted. A btree index is used when output ordering and range queries are desired. Note that the sort depends on the order of the fields in the index keys.
- Unordered, no ranges (hash)
-
Keys are unsorted, and they are evenly distributed (hashed) across the index. A hash index is used for accessing keys based on equality, and are generally best for doing simple lookups.
The relative performance of hash and btree methods depends on many factors, including the distribution of keys in your dataset. We recommend trying both methods if you are in doubt which to use. Remember that StreamBase Studio allows you to specify a key range and sort order using btrees, but not using hash access.