Contents
The Query Table Replication sample shows StreamBase automatic table replication, as well as customized table replication using table delta streams. There are two parts to the sample: a basic sample and custom sample.
-
The basic sample is set of applications and scripts where automatic table replication is enabled.
-
The custom sample is similar, except that it does not enable automatic table replication. Instead it uses a module reference to monitor HA leadership status of the servers. The purpose of the custom sample is to show details to help you customize leadership control to meet your own requirements.
The behavior of the two samples when you run them is the same, except for the specifics of the table replication process.
The samples specify stream-to-stream connections between containers running on separate StreamBase Servers. Both samples make use of the StreamBase automatic high-availability feature.
Note
You might find it useful to read about the use of automatic high availability in High Availability Sample before proceeding with the table replication samples.
Each sample runs a simple application on each of two server instances. At any given time, one server is designated as primary, and the other is designated as secondary. On startup, the primary server is designated as leader, and the secondary is designated as nonleader. The servers coordinate their behavior to provide high-availability access to the sample application's Query Table.
When you enable automatic table replication, as in the basic sample, StreamBase handles the coordination and replication process internally. If automatic table replication is not enabled, as in the custom sample, high availability is handled internally as in the basic sample, but table replication is accomplished by means of additional StreamBase modules.
The sample provides the following kinds of files:
-
orders applications
Provide a very simple example of using a Query Table. You can think of this Query Table as the orders table.
-
table schema definition modules
Provide table schemas imported by the orders applications. (These are StreamSQL files.)
-
replication modules
The replication modules are used only in the custom sample, and they are designed to show how you can customize the table replication process instead of relying on the automatic process. (The replication modules are named with
_SB_as a prefix, as in_SB_repl.sbapp.) -
scripts
There is a set of scripts for the basic sample, and another set for the custom sample. There is also a script used by both the basic and custom scripts. The startup scripts set environment variables, start the primary server, start the secondary server, start a feed simulation, and start a dequeue from all streams.
-
configuration files
In addition to
sbd.sbconf, there are server configuration files for the basic and custom HA servers. It is important to note the<table-replication>section of these files as part of understanding table replication.
The orders modules on both the leader and the nonleader have identical Query Tables, which import ReplTableInterface as a StreamBase table schema. The design pattern of both samples is intended to meet the following requirements:
-
Any nonleader has the ability to create a replica of the orders table if necessary.
-
A module on a new server connecting to the cluster can become the leader if necessary.
Each orders table is maintained as ReplTable. There are two kinds of updates to the replication tables:
- Bulk requests
-
Bulk requests are requests from the nonleader to the leader for a range of table updates. The purpose of bulk requests is to get the nonleader caught up after a network partition, or during initial startup.
- Real time updates
-
Real time updates are table updates that are sent from the leader to the nonleader during normal real time operation. If the nonleader is processing bulk requests it ignores these updates and gets caught up eventually using bulk requests.
On the leader, each change to the orders table causes the corresponding change in the orders table on the nonleader.
The sample_table-repl/apps directory has the applications for both basic and custom samples, as follows:
-
orders.sbapp(automatic table replication is enabled) -
ordersImports.ssql(defines table schema imported byorders.sbapp) -
orders-custom.sbapp(automatic table replication is not enabled) -
orders-customImports.ssql(defines table schema imported byorders-custom.sbapp) -
_SB_repl.sbappand other_SB_files (monitors and handles table replication when automatic table replication is not enabled)
The orders application is a basic example of a high-availability design that uses both automatic high availability and automatic table
replication. This application runs on each server in the high-availability pair. It consumes orders data and determines if
its containing server is the leader. If it is the leader, it updates the orders table on its containing server, and StreamBase
Server takes care of updating the Query Table on the nonleader.
Table replication has been enabled as a property of the orders table, as shown:
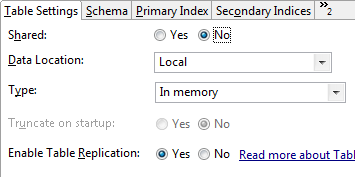 |
In addition, the server configuration file (orders.sbconf) includes the following element as part of the <high-availability> section:
<table-replication>
<!-- HB_OTHER_SERVER: The host name of the other server -->
<param name="HB_OTHER_SERVER" value="${HB_OTHER_SERVER}"/>
<!-- REPL_OTHER_SERVER_PORT: The sbd port on the other host
participating in table replication -->
<param name="REPL_OTHER_SERVER_PORT" value="${REPL_OTHER_SERVER_PORT}"/>
<!-- REPL_CHECK_INTERVAL: Optional parameter (in seconds) which defines
how often do we check the replication state of the table -->
<param name="REPL_CHECK_INTERVAL" value="1"/>
<!-- REPL_BATCH_SIZE: Optional parameter which defines how big the batches
(in tuples) that are sent from the LEADER to the NON_LEADER -->
<param name="REPL_BATCH_SIZE" value="${REPL_BATCH_SIZE}"/>
<!-- REPL_RECONNECT_INTERVAL: Optional parameter which defines how often
(in milliseconds) that reconnects are attempted between the LEADER and
NON_LEADER -->
<param name="REPL_RECONNECT_INTERVAL" value="250"/>
</table-replication>Like orders.app, the orders-custom.sbapp application uses automatic high-availability to monitor and control leadership status between a pair of servers. This application
differs from orders.sbapp in the way it handles table replication as follows:
-
_SB_delta_ReplTableis a table delta stream associated withReplTable, the orders table -
_SB_repl.sbappis a module reference that handles table replication using the table delta stream.
When the nonleader starts up, its orders table is empty. At startup, the replication module (_SB_repl.sbapp) on the nonleader does the following:
-
Attempts to get a bulk entry update from the leader. Real-time updates are ignored while bulk updates are being requested or processed.
-
On intervals of one second, a metronome is fired to ensure that the nonleader is up to date.
-
If the nonleader is not up to date (which is the case on startup), the replication module initiates a bulk entry request to the leader. This request copies entries from the orders table in batches to avoid overwhelming resources such as the server or the network.
-
When the batch update is complete, new orders events are processed in real time by means of a table delta stream.
The replication module uses timeouts to guard against network failures, and it is designed to be resilient if the network fails.
The replication module cannot determine if the container connections are active. If these connections disconnect, the replication module continues to send bulk replication requests on a specified interval.
The following table lists all the environment variables that must be set for the samples to run. The scripts in the sample have settings for the environment variables. If you develop another application based on the applications in the sample, be sure to set the environment variables as required to run the new application.
| Environment Variable | Refers to |
|---|---|
| APP | File name of the application to run. |
| APPSDIR | Directory where the HA applications are located |
| APP_CONTAINER | Container name for the container for APP |
| HB_PORT | Port number for the HA HeartBeat adapter on the other server in a high-availability pair (must be the same value for both servers). |
| HB_OTHER_SERVER | Hostname of the server for the paired StreamBase Server. |
| INITIAL_LEADERSHIP_STATUS | The initial leadership status of the server. Usually the server that starts first is the leader and others are nonleaders. |
| SBD_PORT | Port number to be used by the server. The servers must have different values. |
| REPL_OTHER_SERVER_PORT | Hostname of the other server in the pair of HA servers. |
The folders and files delivered with the Query Table Replication sample are as follows:
| Sample Directory | Contains |
|---|---|
table-repl |
The top level directory of the sample contains:
|
apps |
Contains all of the EventFlow and StreamSQL application files:
Files with a prefix of
|
basic-scripts |
Scripts to run the sample using the basic HA setup and automatic table replication. In this part of the sample, the server does the work of table replication.
|
custom-scripts |
Scripts to run the sample using the basic HA setup and a custom table replication setup. The custom sample shows how to manually create a table replication design pattern.
|
This sample is designed to run in UNIX terminal windows or Windows StreamBase Command Prompt windows, because StreamBase Studio cannot run more than one instance of a server. Nonetheless, it is recommended that you open the application files in StreamBase Studio to study how the applications are assembled. For an introduction to the design of the sample, see the overview at the top of this document.
The table-repl sample is shipped with support for StreamBase authentication disabled. To run this sample with StreamBase authentication enabled, you must perform the following prerequisite steps:
-
Create an authentication database, usually stored in
$STREAMBASE_HOME/etc, using the sbuseradmin command. For instructions, see Using StreamBase Server Simple Authentication. -
In the authentication database, create at least one StreamBase username with the SBAdmin role.
-
Set the following environment variables:
AUTH trueAUTH_PASSWORD_FILE Path to the authentication password file created with sbuseradmin. AUTH_ADMINUSER Username assigned the SBAdmin role in the authentication file. AUTH_ADMINPASSWORD Password for the above username. These variables apply to the HA family of samples, and are not StreamBase standard environment variables.
This section shows how to get the sample running and suggests some steps to show how the servers and the applications work together to ensure high availability. You can, of course, try out other steps of your own, and also use the sample as a starting point for a design pattern that meets your particular requirements.
To get the sample up and running you use scripts that do the following:
-
Start the servers.
-
Start a feed simulation to all streams.
-
Start a dequeue from all streams.
After the sample is running, you can test the high-availability features by entering some data and observing that the Query Tables on both servers are exactly the same.
Because StreamBase Studio can run only one server instance at a time, you must run the two servers in the Query Table Replication sample in terminal or StreamBase Command Prompt windows.
Note
On Windows, be sure to use the StreamBase Command Prompt from the Start menu, not the Windows command prompt.
The steps to run the sample are as follows:
-
Set up five terminal windows.
-
Open five terminal windows on UNIX, or five StreamBase Command Prompt s on Windows.
-
In each window, navigate your Studio workspace copy of the sample.
Note
Note that there are two sets of scripts in two separate folders:
basic-scriptsandcustom-scripts. To run each of the two samples, navigate first to the basic scripts folder, follow the steps for running the sample, then navigate to the custom scripts folder and repeat the steps.
-
-
Start the following processes:
-
In window 1, start the first server with this command:
startprimary.This script starts a server listening on port 9900 and loads the high availability application (
ha) in a container,ha, on that server. The high availability application designates this server as the leader, sets up the required ports, including HB_PORT for the HA Heartbeat adapter, and startsapp. -
In window 2, run
startsecondary.This script is the same as
startprimaryexcept that it starts a server listening on port 9901 and designates this server as the nonleader. Observe that at this point the servers are connected and listening. -
In window 3, run
startfeedsim.A feed simulation starts sending input data to both servers on OrdersIn, an input stream in
orders.sbapp. -
In window 4, run
startdequeue.Dequeuing from
orders.sbappbegins, including dequeuing from_SB_repl.sbapp(namedTableReplicationin the sample).
-
-
Observe the high availability process by terminating the server in window 1.
-
In window 5, run the following command:
sbadmin -p 9900 shutdown
In window 1 the server shuts down.
-
In window 5, enter the command:
sbadmin getLeadershipStatus
Notice that the server on port 9901, which is running in window 2, has become the leader.
-
In window 3 notice that the feed simulation continues to enqueue.
-
In window 4, notice that dequeuing has continued.
-
-
Observe the replication process by sending data to the orders application and observing the Query Table before and after the leader stops running.
-
Start the sample again:
-
Terminate the processes in windows 1, 2, 3, and 4 by pressing Ctrl+C.
-
Start the servers again by running
startprimaryin window 1 andstartsecondaryin window 2. -
In window 3, run sbfeedsim as before, but terminate it shortly after it starts. This step inserts a few rows into
ReplTableon each server.
At this point, the only processes running are in windows 1 and 2, and the leader is running in window 1.
-
-
In window 4, start a dequeuer for the data from the
GetAllOrdersOutstream on the leader as shown:sbc -p 9900 dequeue app.GetAllOrdersOut
No tuples are dequeued yet.
-
In window 3, instead of running the feed simulation, enter some data manually. The
GetAllOrdersInstream inorders.sbapphas a single field of data type integer. You can enqueue any integer value for this field.Type the following command to start enqueuing:
sbc -p 9900 enqueue app.GetAllOrdersIn
Then type any integer as the value, such as:
123
-
In window 4, observe that the results from enqueued data are displayed as rows similar to the following:
TGQO,1,5975.45277797202,IKZW YHDD,2,232.381224838895,OZCQ KUZM,3,7462.41405322331,TVVN XDCZ,4,7223.57119188849,SDMA BJIW,5,9715.46988851713,WPEF
-
In window 1, shut down the leader by ending the process, and observe that window 2 becomes the leader.
-
In window 5, start a dequeuer for the data from the GetAllOrdersOut stream on the new leader as shown:
sbc -p 9901 dequeue app.GetAllOrdersOut
-
In window 3, stop the enqueuing to 9900 and enter some data manually to the new leader.
sbc -p 9901 enqueue app.GetAllOrdersIn
456
The data from
ReplTableis displayed in window 5. Observe that the data is exactly the same as the data in window 4. That is, the Query Table on the new leader is a replica of the Query Table on the leader before it was shut down.
-
In StreamBase Studio, import this sample with the following steps:
-
From the top menu, select → .
-
Select table-repl from the High Availability list.
-
Click OK.
StreamBase Studio creates a single project containing the sample files. The default project name is sample_table-repl.
When you load the sample into StreamBase Studio, Studio copies the sample project's files to your Studio workspace, which is normally part of your home directory, with full access rights.
Important
Load this sample in StreamBase Studio, and thereafter use the Studio workspace copy of the sample to run and test it, even when running from the command prompt.
Using the workspace copy of the sample avoids permission problems. The default workspace location for this sample is:
studio-workspace/sample_table-replSee Default Installation Directories for the default location of studio-workspace on your system.
In the default TIBCO StreamBase installation, this sample's files are initially installed in:
streambase-install-dir/sample/table-replSee Default Installation Directories for the default location of studio-workspace on your system.