Contents
The Map to sub-fields of tuple fields option appears in the Data File Options dialog invoked from the Feed Simulation Editor, when specifying options for a CSV data file used as input for a feed simulation. This option only appears in this dialog if the schema of the input stream for this feed simulation includes at least one field of type tuple.
Use the Map to sub-fields option to specify that the fields of a flat CSV file are to be mapped to the sub-fields of tuple fields, not to the tuple fields themselves. This feature lets Studio read flat CSV files generated manually or generated by non-StreamBase applications such as Microsoft Excel, and apply them to schemas that have fields of type tuple.
Do not enable this option for reading any CSV file whose fields have sub-fields, designated by quotes within quotes according to the CSV standard.
Do not enable this option for reading hierarchical CSV files generated by StreamBase Studio, or by a StreamBase adapter such as the CSV File Writer Output adapter. For example, let's say StreamBase generates a CSV file to capture data emitted from an output stream, whose schema includes tuple fields. In this case, the generated CSV file is already in the correct format to reflect the nested tuple field structure, and does not need further processing to be recognized as such.
Do enable this option for CSV files generated by third-party applications, including Microsoft Excel. These CSV files generally have a flat structure, with each field following the next, each field separated by a comma, tab, space, or other delimiter. Despite the flat structure, if the fields of a CSV file are ordered correctly, you can use the Map to sub-fields option to feed or validate a stream with nested tuple fields.
The examples in this section will clarify this feature.
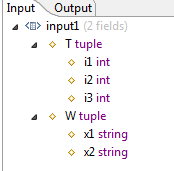
Let's say we have an input stream that has a two-field schema:
T tuple(i1 int, i2 int, i3 int), W tuple(x1 string, x2 string)
This is illustrated in the figure below.
There are two ways to create a CSV file that contains fields that correctly map to this schema:
-
Create a CSV file that contains the expected hierarchy, separated and using quotes within quotes according to CSV standards.
-
Create a flat CSV file that contains the correct number of fields in the right order, then tell StreamBase to interpret this file by mapping to the sub-fields of the two tuples.
The following example shows a hierarchical CSV file that can be used with the schema shown above. In this file, each line maps to two fields, and each field contains sub-fields. To use a CSV file like this example as a feed simulation data file or a unit test validation file in Studio, do not enable the Map to sub-fields option.
"100,200,300","alpha,beta" "655,788,499","gamma,delta" "987,765,432","epsilon,tau"
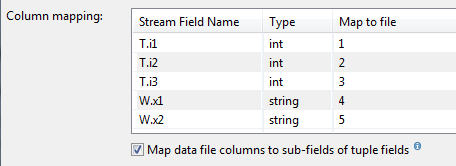
The following example shows a flat CSV file that can also be used with the schema shown above. In this case, you must enable the Map to sub-fields option.
100,200,300,alpha,beta 655,788,499,gamma,delta 987,765,432,epsilon,tau
The following image shows the Column mapping grid of a Data File Options dialog that is reading this flat CSV file. The Map data file columns to sub-fields check box is visible and selected.
 |
When specifying a CSV file to use with a feed simulation, the Data File Options dialog shows you graphically how the CSV file will be interpreted. However, StreamBase cannot fully validate the CSV file against the input port's schema until the application is run.
When using the Map to sub-fields option for a feed simulation, use the following steps to make sure your CSV file is validated as expected:
-
Run the application.
-
Start the feed simulation that uses the CSV file.
-
Examine the resulting tuples in the Input Streams or Output Streams views.
For the example CSV files above, the following Output Streams view shows that the tuples fed to the input stream were interpreted as expected, and all sub-fields were filled with data:
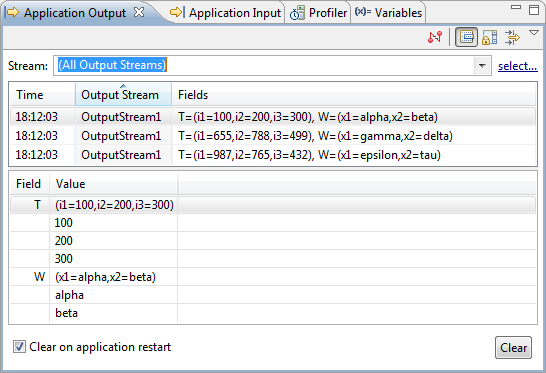 |
The same results are obtained in these two cases:
-
Using the hierarchical CSV file with the Map to sub-fields option disabled.
-
Using the flat CSV file with the Map to sub-fields option enabled.
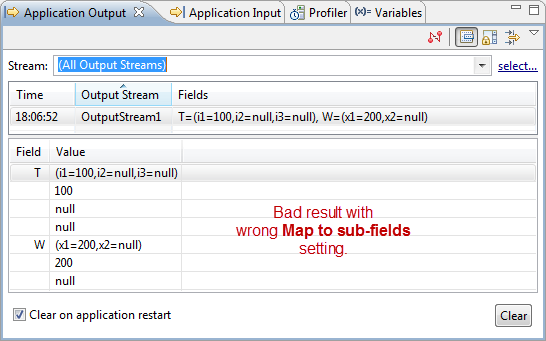
If you see several fields interpreted as null, this indicates that the Map to sub-fields option is enabled for an already-hierarchical CSV file, or that the fields in a flat CSV file do not line up field-for-field with the schema of the input port you are feeding.
The following shows an example of an incorrect result. In this case, only the first sub-field of each tuple received input.
 |