
Contents
![]() The Join operator pairs tuples from two input streams that match a test condition (predicate) and are optionally within
a specified distance on their order fields. The Join operator assumes that each input stream is correctly ordered. It compares
in-order tuples from the first input stream to in-order tuples from the second input stream, within the bounds of the distance
constraint. The results of the joins are released on a single output stream.
The Join operator pairs tuples from two input streams that match a test condition (predicate) and are optionally within
a specified distance on their order fields. The Join operator assumes that each input stream is correctly ordered. It compares
in-order tuples from the first input stream to in-order tuples from the second input stream, within the bounds of the distance
constraint. The results of the joins are released on a single output stream.
Use a Join operator to combine streams having some relationship between the data in both streams. For example, if there were two feeds listing the same equity, the operator could compare the equity price over a time period and emit a tuple if the price in either or both of the streams met particular criteria, such as differing by a specified threshold or if either one exceeded a value.
The remainder of this topic describes the actions that you can take on each tab of the Join operator's Properties view.
Note
In several of the Join operator tabs described in this topic, you use expressions that refer to fields in the input streams.
When it is important to indicate which input stream a field is in, you can qualify the names of the fields by using the conventions
input1.field-name and input2.field-name. The input1. prefix refers to data arriving at the "top" port (#1), while the input2. prefix refers to data arriving at the "bottom" port (#2). Examples: input1.SKU and input2.SKU.
Name: Use this required field to specify or change the name of this instance of this component. The name must be unique within the current EventFlow module. The name can contain alphanumeric characters, underscores, and escaped special characters. Special characters can be escaped as described in Identifier Naming Rules. The first character must be alphabetic or an underscore.
Storage method: Specify settings for this operator with the same in heap and in transactional memory options described for the Annotations tab of the EventFlow Editor. The default setting is Inherit from containing module.
Enable Error Output Port: Select this checkbox to add an Error Port to this component. In the EventFlow canvas, the Error Port shows as a red output port, always the last port for the component. See Using Error Ports to learn about Error Ports.
Description: Optionally, enter text to briefly describe the purpose and function of the component. In the EventFlow Editor canvas, you can see the description by pressing Ctrl while the component's tooltip is displayed.
In the Join Settings tab, specify how the pairing on input data will be done (by values or tuples), when to drop any tuples that have timed out, and the predicate (test condition) on which the join should occur.
- Join by
-
-
Value-based Joins are useful when it is important to have StreamBase return a complete answer rather than an approximate answer. Joining by values means that the values of tuples on one input stream will be compared to the values of tuples on the other input stream.
-
Tuple-based joins are useful when it is unnecessary (or impossible) to have a complete answer (for example, when processing indeterminate or unlimited streams). Tuple-based joins generate approximate solutions to join queries (as are found in SQL statements). Tuples on one input stream will be compared to tuples on the other input stream, regardless of value.
-
- Predicate
-
Specify an expression that evaluates to
trueorfalse. When true, the Join condition is satisfied and the Join operator emits the output that is specified in the Output Settings tab.Note
Your choice of
Join byoptions causes the next tab in the Join Properties view to be titled either Value-based Settings or Tuple-based Settings.
The Value-based Settings tab is available only when you select Join by values on the Join Settings tab. Use this tab to choose the fields you want to order on, and a range of values beyond which the two fields cannot differ:
-
In Ordering Fields, specify the fields on which data from each of the two input ports will be ordered.
-
In the Join Range specify the range of values that ordering fields can contain:
-
Enter the minimum allowable difference between the values of the ordering fields being compared in the two streams.
-
Enter the maximum allowable difference.
In both cases, the difference is expressed as a value relative to the ordering field in the first stream.
The join range acts like a window: the highest order-on field in the buffer sets the upper end of the Join range. If a new tuple arrives that is higher, the range is reset accordingly: any values below that range are removed from the buffer and will be excluded from any joins.
-
In the following example, the join range is 120: the value in Time_C can be 60 less than the value in Time_R, and as large as 60 greater:
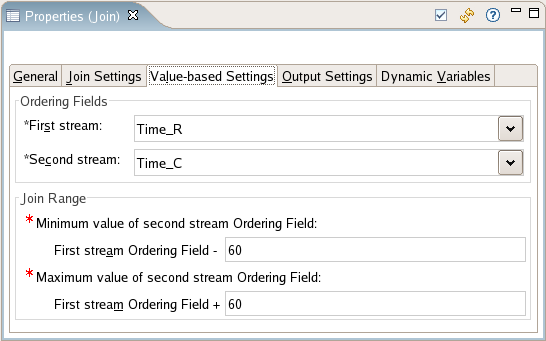 |
Note
Because the Join operator is order sensitive, results are unpredictable if tuples arrive out of order with respect to the ordering fields.
The Tuple-based Settings tab is available only when you select Join by tuples on the Join Settings tab. When you join by tuples, tuples on one input port are compared to tuples on the other input port, regardless of value.
Note
Only tuple-based joins have window sizes, and these windows advance by 1.
- Window Sizes
-
Specify the window size in tuples for the First stream and Second stream, which correspond to the operator's first and second ports. A window size specifies how many tuples of one input port are compared with each arriving tuple on the other input port. As a general rule, the larger the window sizes, the closer the approximate query result will be to a complete answer.
- Tuple timeout
-
The elapsed time in seconds after which tuples are to be flushed from the Join buffer.
The Output Settings tab allows you to specify the field names and expressions this Join operator should release. Release occurs
when the Predicate on the Join Setting tab evaluates to true.
Specify output fields, using one of the two Output options:
-
Choose all input fields option to automatically pass all input fields through to the output stream.
By default, this setting adds prefixes to the names of input fields, as shown in the following screen:
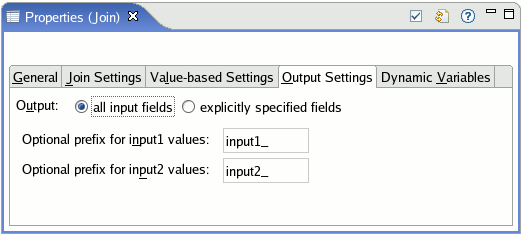
The prefixes are optional and editable. Their purpose is to avoid name conflicts in output fields that might result from joining duplicate field names in the input ports. However, if you change or delete the prefixes and the Join operator fails to typecheck, consider restoring the prefixes.
-
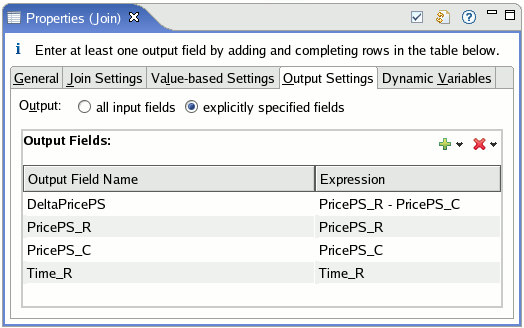
Choose explicitly specified fields to specify the output fields manually.
With the explicit option selected, the Output Fields table is initially empty. Add a row for each output field you want, specifying the Output Field Name and its Expression. Alternatively, use the
 Pass All button to load any or all of the input fields into the table.
Pass All button to load any or all of the input fields into the table.
The following screen shows an Output Fields table that has been edited manually using the explicit option.
Use the Concurrency tab to specify parallel regions for this instance of this component, or multiplicity options, or both. The Concurrency tab settings are described in Concurrency Options, and dispatch styles are described in Dispatch Styles.
Caution
Concurrency settings are not suitable for every application, and using these settings requires a thorough analysis of your application. For details, see Execution Order and Concurrency, which includes important guidelines for using the concurrency options.
This example traces the execution of the Join sample application that is installed with StreamBase. The application combines trades from two feeds, ReutersIn and ComstockIn. The input stream schema contains the following fields: a stock symbol, its price, and its timestamp.
A join occurs when a tuple on one port matches a tuple on the other port. To match, the two tuples must have the same stock symbols, and the difference in price must be greater than or equal to 1, using the following expression
Symbol_R == Symbol_C && abs(PricePS_R - PricePS_C) >= 1.0
In addition to the price difference expression, a distance constraint is set so that matched pairs must have timestamps within 60 seconds of each other. Output tuples contain the difference in price between the matched tuples, the price per share from each, and the time value from the Reuters tuple.
Each step of this example shows a new tuple being enqueued to the Join operator, and any output tuples that are released. The contents of the two operator buffers are shown after each tuple arrives and after any tuples are released.
-
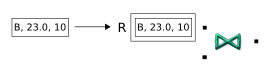
A tuple enters the Join operator on the ReutersIn input port (here shortened to R) and is stored in the buffer:
-
A tuple enters on the ComstockIn port (shortened to C). The value of its first field (B) matches the symbol in the first tuple, but the price difference (in the second field) is less than one. Therefore, nothing is released by the Join operator:
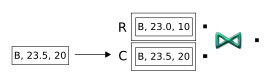
-
A tuple on the R port has a match on the other port, and its price difference is 1. The conditions for the join operation are met, and the Join operator emits an output tuple:

-
A tuple is enqueued that contains a new stock symbol (A). Because it does not match any existing tuples, no output is produced:
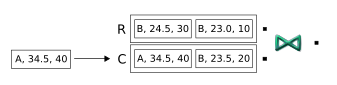
-
A tuple arrives on the C port whose symbol matches two tuples from the other port. In both cases, the price difference is greater than 1. As a result, two tuples are released - one for each match:

-
A new tuple matches the symbol of one existing tuple on the other input port, with price difference of 2. Therefore, the Join operator emits another tuple:

-
The last tuple, enqueued on the C input port, matches two tuples on the R port. However, the new tuple causes the range of time values in the matching tuples to exceed the specified join range of 60 seconds. The new tuple advances the high end of the range to 100, and the other matching tuples are now below the join range. As a result, the matching tuples on the other port are purged from the buffer, and no output is emitted:

This example traces the execution of a tuple-based Join operation. The application is simple enough to clearly illustrate the basic idea of a tuple-based join. Each input port contains only two fields: a stock symbol and a price. The Join operator pairs tuples that match in both fields. The Window sizes are set to 3 for the first input port, and 2 for the second input port. When a join occurs, the output tuple includes the matched symbol and price values.
Each step of this example shows a new tuple being enqueued to the Join operator. The contents of the two windows are shown after each tuple arrives and after any tuples are released. The windows can be said to "move" over the stream of data: notice that when the number of arriving tuples exceeds a window's allocated size, the oldest tuples are dropped from the window.
-
To begin, four tuples are enqueued. Tuples entering on the first input port are buffered in the Join operator's first window, and those entering on the second port are stored in the second window. No output occurs yet, because none of the tuples entering the first port matches any from the second port:
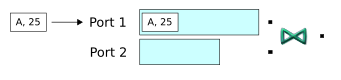
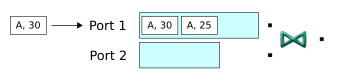
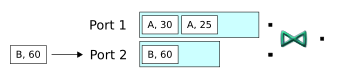
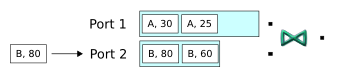
-
Next, a tuple enters the second input port, and it matches a tuple in the first buffer. Therefore a Join occurs, and the operator releases a matching tuple. In addition, notice that when the window is full and a new tuple arrives, the window advances over the stream of tuples: the oldest tuple in the window (B, 60), is flushed from the window.

-
Now, a sixth tuple entering the first input port fills the first input port's window. Note that no output occurs: recall that the matching tuple that was stored earlier in the other window was dropped in the preceding step.
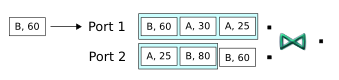
-
Finally, another tuple entering on the first input port causes its window to advance and flush its oldest tuple. Meanwhile, the new tuple matches one still stored in the second window, so the Join operator releases a tuple.
