Contents
Any StreamBase® Managed Object can be a distributed object. A distributed object transparently provides remote method invocation and access to object fields across nodes. The full transactional guarantees made by StreamBase® for non-distributed objects are also true for distributed objects.
Access to a distributed object is through a normal Java object reference. All Managed Object references contain data to identify the node where the object was created.
The same instance of an object cannot exist on multiple nodes. Copies of an object's state may be located on multiple nodes to improve performance or robustness, but the master copy is located on a single node — by default the node where the object was created.
All object methods transparently run on the master node for an object. Any methods invoked on an object reference are sent to the master node and executed there.
Objects of the same type can be created on multiple nodes. This is done by installing the application class files, or implementation, on multiple nodes. This is a common application architecture to support object partitioning and caching or service availability mechanisms.
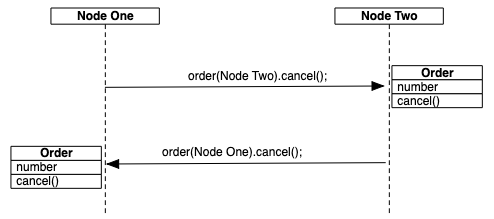
Figure 1, “Distributed method execution” shows an Order class that has its implementation installed on two nodes — Node One and Node Two. Two instances of the Order class have been created, one on Node One and one on Node Two. When the Order.cancel() method is executed on Node One, using the order(Node Two) instance, the method is executed on Node Two. The opposite is true for the order(Node One) instance.
The distribution protocol uses either TCP/IP, TLS, or Infiniband connectivity between nodes with a platform independent encoding. The platform independent encoding allows heterogeneous hardware platforms to communicate with each other in a distributed transactional system.
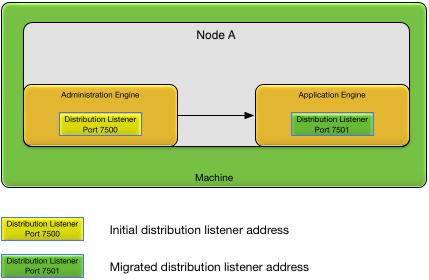
When a node is started a distribution listener is started in the node administration engine. As application engines start, the distribution listener is automatically migrated to the new application engines. Listener migration is done to improve the performance of distributed communication from application engines by eliminating inter-process communication. When a distributed listener is migrated to a new engine, the listener is left active on the old engine, but no new connections are created to that listener.
StreamBase® provides location transparency for objects. This means that when an application accesses an object, its location is transparent — it may be on the local or on a remote node.
Location transparency is accomplished through the use of distributed references. All Managed Objects created in StreamBase® have a distributed reference that contains the master node for the object. An object's identity, as defined by its distributed reference, does not change through-out the lifetime of the object.
Methods invoked on an object are always executed on the master node for an object.
Object field data is transparently read from and written to the master node when fields are accessed on a local node.
Read operations are dispatched to the master node to read field data depending on whether the local node has the data cached locally or not. If the field data is not available on the local node a distributed read will be done when a field is accessed. The read will complete before the get of the field returns to the caller. All reads are done on the master node in the same transaction in which the field access occurs.
When an field associated with a remote object is modified on a local node, by default, the update is deferred until the local transaction enters the prepare state. This is called deferred writes. See Deferred Write Protocol for details.
When an extent is accessed using a local query, only object references on the local node are returned — no read is dispatched to any remote nodes. References are in a local extent either because the object was created on the local node, it was returned in a method call, or it was pushed to the local node as part of object replication. Distributed queries can be used to access the global extent of all objects.
Every node is uniquely identified by:
-
a cluster unique name
-
a cluster unique location code
-
a cluster unique shared memory timestamp
The default node name is set to the local host name. The default node name can be changed during node installation. This allows multiple StreamBase® nodes to run on the same machine.
The location code is automatically derived from the node name using a hashing algorithm.
The location code is a numeric identifier that is used to determine the actual network location of the master node for an object. The location code is stored with each Managed Object. The initial value of the location code for an object is the location code of the node on which the object was created.
Highly available objects can migrate to other nodes as part of failover, or to support load balancing. When object migration occurs the location code associated with all of the migrated objects is updated to use the location code of the node to which they were migrated. This update occurs on all nodes on which the objects exist. After the completion of an object migration, the new master node for the object is the new node, which may be different than the node on which the object was created.
The shared memory timestamp is assigned when the shared memory is first created for a node. This occurs the first time a node is started following an installation. The shared memory timestamp is a component of the opaque distributed reference. It ensures that the distributed reference is globally unique.
Location discovery provides runtime mapping between location codes, or node names, and network addresses. This is called location discovery. Location discovery uses the service discovery mechanisms described in Discovery Service.
Location discovery is done in one of two ways:
-
dynamic discovery.
-
proxy discovery using configuration information.
The service discovery protocol can be used to discover location names. This has the advantage that no configuration for remote nodes has to be done on the local node — it is all discovered at runtime. This is called dynamic discovery.
Configuration can also be used to define the mapping between a node name and a network address. Configuring this mapping is allowed at any time, but it is only required if service discovery cannot be used for location discovery. An example of when this would be necessary is if a remote node is across a wide area network where service discovery is not allowed. This is called proxy discovery. See Proxy Discovery for more details.
Warning
When a network address is discovered with both dynamic and proxy discovery, the configured proxy discovery information is used.
Location discovery is performed in the following cases:
-
A create of an object in a partition with a remote active node.
-
A method is called or field is set on a remote object.
When an object is associated with a partition whose active node is remote, a location discovery request is done by node name, to locate the network information associated with the node name.
When an operation is dispatched on a remote object, a location discovery request is done by location code, to locate the network information associated with a location code.
Location code information is cached on the local node once it has been discovered.
Initialization and termination of the distribution services are tied to node life cycle (see Nodes). When a node is installed the following steps are taken to initialize distribution:
-
Mark the local node state as starting
-
Start dynamic discovery service if enabled
-
Start network listeners
-
Start keep-alive server
-
Mark the local node state as
Up(see Remote Node States).
After initialization completes, the node is automatically part of the cluster. It can now provide access to distributed objects or provide high-availability services to other nodes in the cluster.
Remote nodes can have one of the states in Remote node states.
Remote node states
Application installed node state change notifiers are called when a remote node transitions from active to unavailable and from unavailable to active. The In Up Notifier and In Down Notifier states defined in Remote node states are seen when a node notifier is being called.
When a node state change notifier is installed, it is guaranteed to be called for all active remote nodes already discovered by the local node. Node notifier execution is serialized for a specific remote node. A call to a notifier must complete before another notifier is called. For example, if a remote node becomes unavailable while an active notifier is being executed, the unavailable notifier is not called until the active notifier completes.
Node state change notifiers are called in a transaction.
By default, all distributed object updates use a deferred write protocol. The deferred write protocol defers all network I/O until the commit phase of a transaction. This allows the batching of all of the object updates, and the prepare request, into a single network I/O for each node, improving network performance. The size of the network buffer used for the network I/O is controlled in the distribution configuration. See the StreamBase® Administration for details on distribution configuration.
The deferred write protocol is shown in Figure 3, “Deferred write protocol” for two nodes.

Notice that no transaction locks are taken on node B as distributed objects are modified on node A until the prepare step.
Note
Distributed object creates and deletes perform network I/O immediately, they are not deferred until commit time. There is no prepare phase enabled for these transactions. See Figure 1, “Distributed transaction”.
The deferred write protocol is disabled if a method call is done on a distributed object. Any modifications to the distributed object on the local node are flushed to the remote node before the method is executed on the remote node. This ensures that any updates made on the local node are available on the remote node when the method executes.
After the method executes on the remote node any modifications on the remote node are copied back to the initiating node. This ensures that the data is again consistent on the local node on which the method was originally executed.
The deferred write protocol can be disabled in the high availability configuration. In general, it should be enabled. However, if an application only accesses object fields using accessors, instead of directly accessing fields, it will be more performant to disable the deferred write protocol since no modifications are ever done on the local node. See the StreamBase® Administration for details on high availability configuration
StreamBase® supports keep-alive messages between all nodes in a cluster.
Keep-alive requests are used to actively determine whether a remote node is still reachable.
Keep alive messages are sent to remote nodes using the configurable keepAliveSendIntervalSeconds time interval.
Figure 4, “Keep-alive protocol” shows how a node is detected as being down. Every time a keep-alive request is sent to a remote node, a timer is started
with a duration of nonResponseTimeoutSeconds. This timer is reset when a keep-alive response is received from the remote node. If a keep-alive response is not received
within the nonResponseTimeoutSeconds interval, a keep-alive request is sent on the next network interface configured for the node (if any). If there are no other
network interfaces configured for the node, or the nonResponseTimeoutSeconds has expired on all configured interfaces, all connections to the remote node are dropped, and the remote node is marked Down.
Connection failures to remote nodes are also detected by the keep-alive protocol. When a connection failure is detected, as opposed to a keep-alive response not being received, the connection is reattempted to the remote node before trying the next configured network interface for the remote node (if any). This connection reattempt is done to transparently handle transient network connectivity failures without reporting a false node down event.
It is important to understand that the total time before a remote node is marked Down is the number of configured interfaces times the nonResponseTimeoutSeconds configuration value in the case of keep-alive responses not being received. In the case of connection failures, the total
time could be twice the nonResponseTimeoutSeconds times the number of configured interfaces, if both connection attempts to the remote node (the initial one and the retry)
hang attempting to connect with the remote node.
For example, in the case of keep-live responses not being received, if there are two network interfaces configured, and the
nonResponseTimeoutSeconds value is four seconds, it will be eight seconds before the node is marked Down. In the case of connection establishment failures, where each connection attempt hangs, the total time would be sixteen seconds
before the node is marked Down.

Distribution uses TCP as the underlying network protocol. In general, TCP provides reliable connectivity between machines on a network. However, it is possible that network errors can occur that cause a TCP connection to drop. When a TCP connection is dropped, requests and responses between nodes participating in a distributed transaction are not received. Network errors are detected by the keep-alive protocol described in Detecting Failed Nodes and handled by the distributed transaction protocol.
Network connectivity failures are caused by:
-
A non-response keep alive timeout occurring.
-
TCP retry timers expiring.
-
Lost routes to remote machines.
These errors are usually caused by network cables being disconnected, router crashes, or machine interfaces being disabled.
As discussed in Local and Distributed Transactions, all distributed transactions have a transaction initiator that acts as the transaction coordinator. The transaction initiator can detect network failures when sending a request, or reading a response from a remote node. When the transaction initiator detects a network failure, the transaction is rolled back. Other nodes in a distributed transaction can also detect network failures. When this happens, rollback is returned to the transaction initiator, and again the transaction initiator rolls back the transaction. This is shown in Figure 5, “Connection failure handling”.

When the transaction initiator performs a rollback because of a connection failure — either detected by the initiator or another node in the distributed transaction, the rollback is sent to all known nodes. Known nodes are those that were located using location discovery (see Location Discovery). This must be done because the initiator does not know which nodes are participating in the distributed transaction. Notice that a rollback is sent to all known nodes in Figure 5, “Connection failure handling”. The rollback is retried until network connectivity is restored to all nodes.
Transaction rollback is synchronized to ensure that the transaction is safely cancelled on all participating nodes, no matter the current node state.
Any communication failures to remote nodes detected during a global transaction before a commit sequence is started cause an exception that an application can handle (see the StreamBase® Transactional Memory Developers Guide). This allows the application to explicitly decide whether to commit or rollback the current transaction. If the exception is not caught, the transaction will be automatically rolled back.
Undetected communication failures to remote nodes do not impact the commit of the transaction. This failure scenario is shown
in Figure 6, “Undetected communication failure”. In this case, Node 2 failed and was restarted after all locks were taken on Node 2, but before the commit sequence was started by the transaction initiator — Node 1. Once the commit sequence starts it continues to completion. The request to commit is ignored on Node 2 because the transaction state was lost when Node 2 restarted.

Transaction initiator node failures are handled transparently using a transaction outcome voting algorithm. There are two cases that must be handled:
-
Transaction initiator fails before commit sequence starts.
-
Transaction initiator fails during the commit sequence.
When a node that is participating in a distributed transaction detects the failure of a transaction initiator, it queries all other nodes for the outcome of the transaction. If the transaction was committed on any other participating nodes, the transaction is committed on the node that detected the node failure. If the transaction was cancelled on any other participating nodes, the transaction is cancelled on the node that detected the failure. If the transaction is still in progress on the other participating nodes, the transaction is cancelled on the node that detected the failure.
Transaction outcome voting before the commit sequence is shown in Figure 7, “Transaction initiator fails prior to initiating commit sequence”. In Figure 7, “Transaction initiator fails prior to initiating commit sequence” the initiating node, Node 1, fails before initiating the commit sequence. When Node 2 detects the failure it performs the transaction outcome voting algorithm by querying other nodes in the cluster to see if
they are participating in this transaction. Since there are no other nodes in this cluster, the Transaction Status request is a noop and the transaction is immediately cancelled on Node 2, releasing all locks held by the distributed transaction.

Transaction outcome voting during a commit sequence is shown in Figure 8, “Transaction initiator fails during commit sequence”. In Figure 8, “Transaction initiator fails during commit sequence” the initiating node, Node 1, fails during the commit sequence after committing the transaction on Node 2Node 3Node 3 detects the failure it performs the transaction outcome voting algorithm by querying Node 2 for the resolution of the global transaction. Since the transaction was committed on Node 2 it is committed on Node 3.

To support transaction outcome voting each node maintains a history of all committed and cancelled transactions for each remote node participating in a global transaction. The number of historical transactions to maintain is configurable and should be based on the time for the longest running distributed transaction. For example, if 1000 transactions per second are being processed from a remote node, and the longest transaction on average is ten times longer than the mean, the transaction history buffer should be configured for 10,000 transactions.
For each transaction from each remote node, the following is captured:
-
global transaction identifier
-
node login time-stamp
-
transaction resolution
The size of each transaction history record is 24 bytes.