Contents
Schemas are described with different terms in StreamBase, depending on context and intended use:
- Private Schemas
-
Private schema is StreamBase Studio's term for unnamed schemas. In Studio, you create a private schema in a component's Properties view by adding rows directly in the Fields grid of an Edit Schema tab. You also create a private schema when you add a row of type
tuple, and use the button ( ) to add new subrows.
) to add new subrows.

- Named schemas
Named schemas are schemas defined and named in an EventFlow module or in a StreamBase interface file. Named schemas can be referenced by name in any component of the module in which they are defined, or in modules that import the defining module or interface. When you modify a named schema, all components that reference it automatically inherit those changes.
You can create named schemas in the Interface tab of the Interface Editor or in the Definitions tab of the EventFlow Editor. Named schemas are discussed further in Using Named Schemas.
- Empty schemas
An empty schema is a schema with no fields defined. Empty schemas allow a module to pass typechecking before all schemas have been defined, or to create an input stream that triggers a downstream action without having to enter a dummy input value. See Using Empty Schemas.
- Table schemas
A table schema is a named schema for a set of Query Tables that completely defines the structure of those Query Tables, and ensures that all Query Tables in the set are identically defined. A table schema includes the table structure of a Query Table, as well as its primary index and secondary indexes (if any). You can apply a table schema by name to two or more Query Tables to quickly assign the same structure to Query Tables in several modules across a large application. Table schemas are only used with StreamBase Query Tables, and not with JDBC tables.
In a table schema, the table's row structure can be defined with a private schema or a named schema. Thus, a table schema with a particular name often includes a named schema with another name.
- Parent Schemas
Any schema can extend a parent schema, which must be a named schema in the same module or on the module search path. The child schema inherits all fields from the parent, and can then add more fields appropriate for the context. In the child schema, you cannot subtract or modify parent fields, but you can override an abstract parent field declared with a capture field. See Using Parent Schemas and capture fields.
- Nested schemas
A nested schema is a field of type tuple contained in a schema. In EventFlow modules, both private schemas and named schemas can be used as nested schemas.
- Imported and exported schemas
You can import one or more named schemas and table schemas from a StreamBase interface or EventFlow module to another interface or module.
-
In the EventFlow Editor, use the button in the Definitions tab.
-
In the Interface Editor, use the button in the Imports tab.
-
The following comparison further clarifies the difference between schema types.
- Private vs Named Schemas
-
In StreamBase Studio, use private schemas for components in small EventFlow fragments, or for components with a different schema than other components in your fragment. Defining a private schema does not mean that the schema is restricted to the component for which it is defined. As with all schemas in StreamBase, private schemas are automatically inherited by all downstream components.
Use named schemas for three primary reasons:
-
For developer convenience, especially in large EventFlow fragments. When editing the schema of a new component, specify the name of a named schema instead of retyping the same schema definition.

-
For automatic updating of a schema in wide use in your application. When you define new schemas as a named schema, you only need to update the schema in one place. You can edit the named schema once, and all instances of that schema are automatically updated.
-
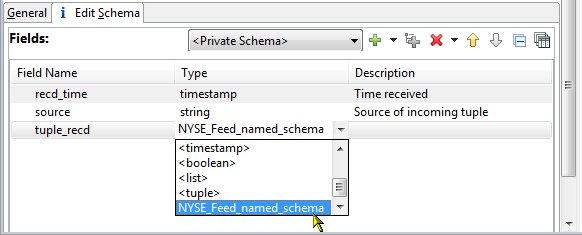
To define a field of type tuple. Certain data streams have hierarchical layers, where the second layer is a schema within the primary schema. You can create a field with the data type tuple and assign it individual, private subtuple rows, or you can use the name of a named schema as a data type when defining the new tuple field. In the following example, we are defining a three-field schema whose third field is a named schema.
The names of named schemas become a data type for the module in which the named schema is defined or imported. The list of data types to assign to a field includes all named schemas:
-