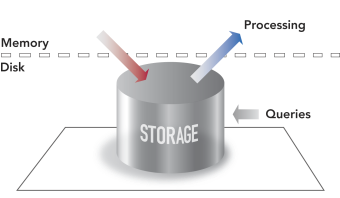
StreamBase is a computing platform designed specifically to meet the performance requirements of high-volume, real-time streaming applications. At its core, StreamBase implements a unique stream processing engine named StreamBase Server. In contrast to the traditional database model where data is first stored and indexed and then subsequently processed by queries, StreamBase processes the inbound data while it is in flight, as it streams through the server.
Data arrives on a stream as discrete messages called events. Each message contains a tuple, and is processed by StreamBase Server in real time, using the business logic that you defined. Results are delivered as they are produced, typically in milliseconds. Events are inherently transient: their data can be stored, but storage is optional. In many cases, client programs that you write will consume the processed results in real time, and take appropriate actions based on your code's direction.
StreamBase can also connect to an external data source, enabling applications to incorporate selected data into the application flow, or to update the external database with processed information.
The following diagrams illustrate the conceptual differences between the older Outbound Processing model and the StreamBase Inbound Processing model.
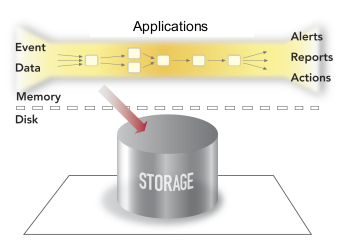
In StreamBase applications, events are represented by data records called tuples that flow through the query and application processing steps, which may in turn produce new events with data derived from this data. Tuples consist of one or more name-value pairs of data, called fields. Each field value has a specific data type. StreamBase provides a set of operators, which are data processing units that you can add and configure to apply your business logic on the streaming data. With the operators and a supporting cast of data constructs, you can perform such tasks as:
-
Applying aggregating functions to windows of real-time data.
-
Computing new field values by applying mathematical expressions, adding new fields, or dropping fields, from the data streams.
-
Filtering data into separate streams for conditional processing.
-
Joining previously split streams of data based on key values.
-
Within the StreamBase application's process, populating a shared data table so that other portions of the application can look up data based on key values.
StreamBase also features a graphical development environment named StreamBase Studio, which lets you design and test streaming applications, and prepare them for deployment.
For developers, StreamBase provides a graphical programming environment plus command-line tools to build streaming applications quickly and efficiently.
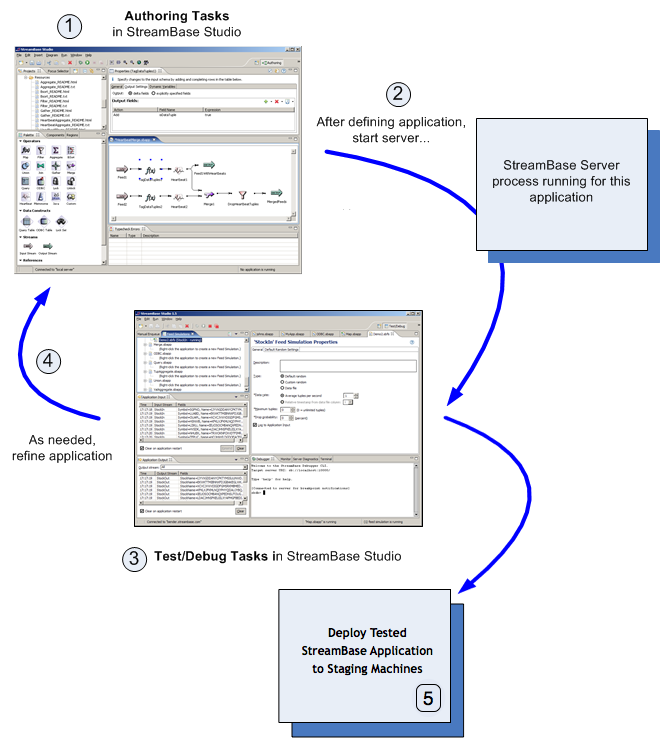
In StreamBase Studio, the SB Authoring perspective lets you design StreamBase applications graphically, using the TIBCO® StreamBase EventFlow language. As part of the design stage, you define properties for operators and other components that apply your business logic on the inbound data.
During development, you can use StreamBase Studio to start a StreamBase Server instance. StreamBase Server loads the application, processes the inbound data according to your definitions in the operators, and responds to any other requests, such as requests for data from Java, C++, or .NET clients that you write.
Once the server is started, StreamBase Studio opens a second perspective, SB Test/Debug, that contains tools to enqueue or dequeue data on the running application, or to run a debugger to pause the application and step through its processing units.
Finally, StreamBase provides Client API libraries for Java, C++, Python, and on Windows, .NET, that you can use to develop client applications that enqueue to (or dequeue data from) StreamBase applications. We provide examples of writing enqueuer clients (sometimes called producers) that feed data into the application, and dequeuer clients (sometimes called consumers) that accept data from the application for further processing.
The following diagram illustrates the StreamBase development cycle and platforms.