Contents
A stream is a sequence of data records called tuples. A tuple is similar to a row in a database table. In a high-volume streaming application, streams flow into the application and are processed in real time, before any optional on-disk storage occurs.
The tuples in a stream have a schema, which defines each field's name, data type, and position. A field is simply a named value in a tuple, such as a stock's
Symbol in a trade record. A field is similar to a column in a database table. The following diagram illustrates a stream of data
containing tuples:

A schema for the stream in the above diagram is:
| {Symbol string, |
| Name string, |
| Description string, |
| Volume int, |
| Price double} |
During the course of processing streaming data, you can dynamically add, remove, or modify the fields that comprise the tuples. That is, the initial schema of a stream does not determine its contents during the entire processing execution.
An important step in building any application is determining which fields will comprise the inbound data, how that data should be organized, named, and typed, and which fields will contain key values. You have often already made those metadata decisions for your existing applications, and you want to know how to define the schemas for StreamBase. We will introduce the schema definition steps later in this tutorial. For now, notice how in the screen below, the schema for an application component is defined:
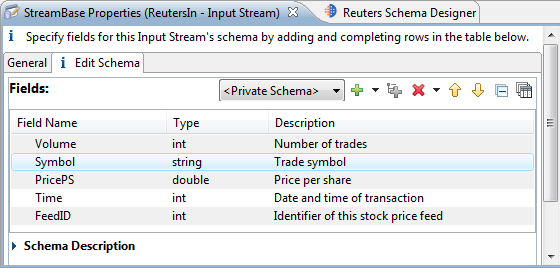
The image above is a peek at one of many features in StreamBase Studio.
The entry points for a StreamBase application are called input streams. Your application can define one or more input streams. The previous sample screen showed the schema definition for a stock trading input stream. But how is data sent to a named input stream? The options are:
-
From an adapter program that performs the conversion from an external source, such as a stock market data feed, into the StreamBase tuple protocol. For example, StreamBase provides an adapter that converts TIBCO® Rendezvous™ messages into StreamBase tuples, and vice versa.
-
From an enqueue client program (Java, C++, Python, or .NET) that submits inbound data to one or more input streams defined in your StreamBase application. A client extends the StreamBase Client API to interact with a running StreamBase application.
-
From an external database connected to your StreamBase application, using SQL queries to read the data. This method allows your application to work with historical data along with the streaming data from its input streams.
-
From StreamBase commands in terminal windows to enqueuing operations.
-
From a StreamBase feed simulation, which allows you to enqueue generated data or recorded data from a CSV input file or JDBC database.
You can define output streams that serve as named exit points in your StreamBase application. There are several ways to perform dequeue operations:
-
Using an adapter program that can return the processed data from StreamBase to the original external source.
-
Using a dequeue client program that listens for outbound data on the application's streams. A client can be written in Java, C++, Python, or .NET.
-
Using insert or update queries to an external JDBC-compliant data source that is connected to your StreamBase application.
-
Using StreamBase Studio's Application Output view while running or debugging the application in Studio.
-
Using a StreamBase command in a terminal window.
The following high-level diagram illustrates the different ways that data can enter and exit a running StreamBase application.
A set of standard adapters is provided with your StreamBase license. Premium adapters are available separately from TIBCO, based on the terms of your license.
StreamBase Studio supports both graphical and text-based application development:
-
EventFlow applications are XML files that are edited graphically using StreamBase Studio's EventFlow Editor.
-
StreamSQL applications are coded using a query language to describe the application and query streams of data. StreamSQL Applications are stored in text files with a
.ssqlextension.
You can also build parts of applications, called modules, that can be included as components in other applications. In fact, any EventFlow or StreamSQL file can be used as a module in another application.
To create an EventFlow application in StreamBase Studio, you can drag and drop the icons for various components from the Palette View to the EventFlow Editor's drawing canvas. The components include:
-
Input streams and output streams.
-
Operators that can apply your business logic on streaming data, such as aggregating tuples, or merging tuples, or retrieving data from a table. Each operator performs the work that you specify in its Properties view.
-
Data constructs that store information used by an associated StreamBase operator. For example, Query operators are associated with Query Table data constructs.
We will use some of these components during the tutorial, and you can read more about them in the Authoring Guide.
The following image shows dragging a Query Table component from the left-side Palette view to the EventFlow Editor's drawing canvas.
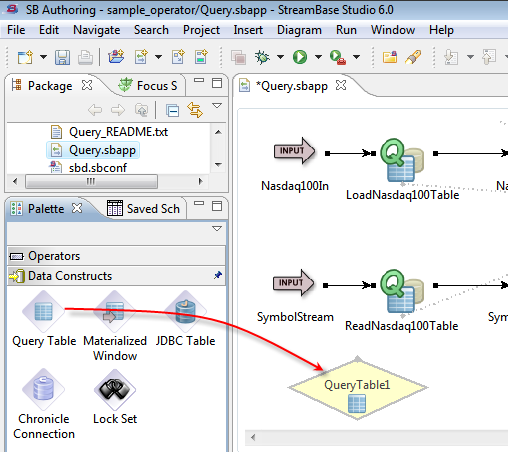
Once a component is placed on the canvas, you define its runtime behavior by setting parameters and defining expressions in its Properties View.
StreamSQL is a SQL-like language you can use to develop StreamBase modules. StreamSQL is no longer the recommended approach for new applications, but is supported for existing applications. The StreamSQL language is not expected to receive updates and new features. Consider using EventFlow modules for all new application development.
Consult the StreamSQL Guide for guidance on maintaining StreamSQL modules.