This article provides an overview of StreamBase® applications. Although some details will vary from one application to another, the conceptual framework presented in this chapter (and this book) is common to all, and forms the basis for understanding later chapters. The concepts explained in this chapter include:
-
application context within a business solution
-
developing an application
-
deploying an application
-
a brief overview of the platform services that impact application design
Contents
Additional details on designing and deploying applications can be found in the Transactional Memory Developers Guide and Administration Guide respectively.
An application forms part of a business solution as shown in Figure 1, “Business Solution”. A business solution may consist of one more applications deployed to a number of nodes grouped into a cluster. Each cluster hosts a single application. Each node is a container for one or more engines on which an application executes. Applications are described in more detail in Design Time, and clusters, nodes, and engines are described in more detail in Deploy Time and in Deployment.
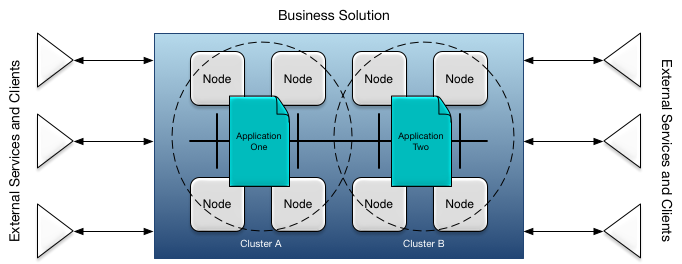
Some important properties of applications:
-
distributed: applications are transparently distributed across various machines.
-
highly available: if one machine fails, processing of in-flight and new transactions can continue uninterrupted on another machine.
-
elastic: machines can be added or removed as needed based on the current load.
-
extensible: applications can be upgraded with changed, or entirely new, behavior without a service outage.
-
configurable: applications are highly configurable with configuration changes occurring without interrupting in-progress work.
-
geographically redundant: applications can be deployed across wide-area networks to support disaster recovery.
-
discoverable: applications are discoverable using a discovery service to eliminate any dependency on actual machine network addresses.
Applications are generated as part of a software development process. This process is collectively called design-time and consists of standard software development tasks. The output of the design-time tasks is an application archive which contains everything required to deploy an application.
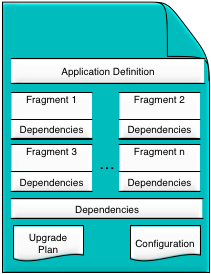
An application archive contains all of the details known at design-time by a developer or an architect. It does not contain, other than possible default values, any deployment time details, for example network topology information. The contents of an application archive are:
-
an application definition.
-
one or more fragments.
-
optional application dependencies, 2 3rd-party JAR files or native libraries.
-
optional default application configuration.
-
optional upgrade and restore plans.
A fragment is an executable part of an application. A fragment consists of:
-
executable software.
-
optional fragment dependencies, such as 3rd-party JAR files or native libraries.
-
optional default fragment configuration.
Each fragment has a fragment type, which identifies the type of engine that will run the fragment at deployment time, for example Java.
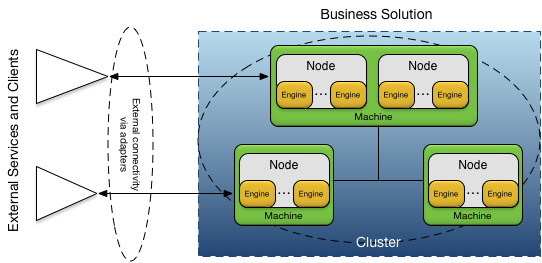
An application is deployed onto a cluster of nodes providing high-availability, elastic scaling and distributed administration. The application nodes are interconnected using distribution, and connected to external systems using adapters. This is shown in Figure 3, “Deployed application”.
Applications are deployed to nodes in a cluster using the application archive generated at design-time and an optional node deploy configuration. A node deploy configuration is used to:
-
specify deployment time configuration values, for example port numbers, host names, memory sizes, etc.
-
override default configuration in an application archive.
-
add additional deployment time configuration, for example administration users.
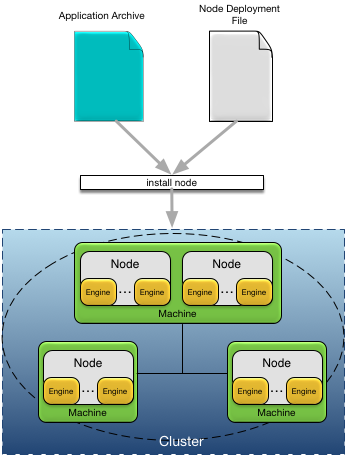
When an application is deployed, a cluster name and a node name are specified as part of deploying the application to a node. All nodes on which an application is deployed belong to the same cluster. See Service Names for more details on cluster and node names.
A node is a container that runs one or more engines to run the fragments in an application. An engine is an execution context that is specific to the fragment type. For example, a Java fragment would run on an engine with its own JVM. Each fragment in an application is executed on one or more engines. A complete description of node and engine life cycle can be found in Nodes.
Applications use the services of the StreamBase® platform. These services include:
-
transaction management
-
transparent distribution of data and processing
-
a security model
-
high-availability and distribution
-
extensible configuration service
-
extensible management services
-
adapter framework to provide connectivity to external systems
While the StreamBase® platform provides a set of powerful capabilities, it is the combination of the application-specific logic and configuration that define the actual behavior of the business solution, as shown in Figure 5, “Platform services”.
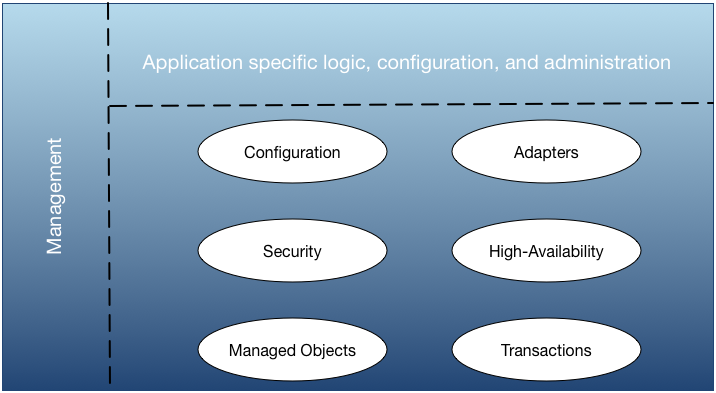
Notice that Figure 5, “Platform services” shows management not only across the StreamBase® platform, but also across the application-specific part of the solution as well. This is because the management service is extensible to the entire application, so you can manage the entire application in a consistent way.
The following sections provide a high-level overview of the platform services that most impact application design.
The behavior of a business solution can be changed by activating different configurations. Many aspects of a solution are configurable, from minor changes to wholesale redefinition of business logic. Distribution, security policy, adapter connectivity options, and many other features of a solution are configured using the StreamBase® configuration service. The configuration service provides:
-
support for application specific configuration.
-
a standard syntax to express configuration data.
-
a unified identification for configuration using a configuration type, name, and version.
-
a unified set of administrative commands to manage configuration.
-
notification when configuration states change.
The configuration service loads configuration data from files. The syntax of the configuration files is Human-Optimized Configuration Object Notation (HOCON). HOCON is a superset of JavaScript Object Notation (JSON), enhanced for readability. Configuration files contain the configuration type, name, and version identifiers, along with the configuration data. Configuration files can be loaded from any machine that has connectivity to the machine running the target node. Configuration can also be loaded on multiple nodes at the same time.
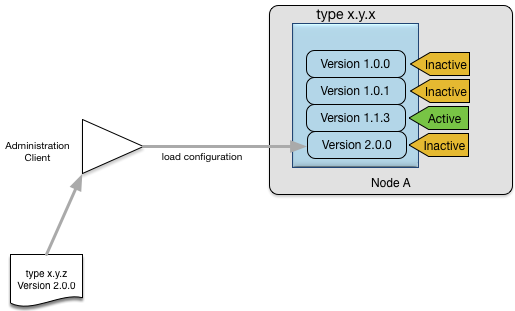
There are many different configurable elements in an application; each one can have several different versions loaded but
only one active version. Figure Figure 6, “Loading a new configuration” shows an example of how you might load a new version 2.0.0 of an adapter configuration x.y.z, while leaving the current version 1.1.3 as the active version.
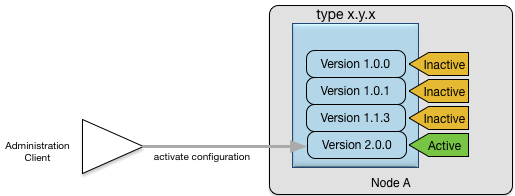
There can be any number of different versions loaded for a particular configuration type; any of these can be activated by
a management command. Figure 7, “Changing the active configuration” shows an example of the activation of version 2.0.0 of an adapter configuration type x.y.z. The previously active version, 1.1.3, is now inactive.
Applications communicate with external systems and other nodes in a cluster using:
-
adapters, which provide connectivity between a node and external systems.
-
a distributed communication model to transparently communicate between nodes.
Each of these is configurable and controllable using the standard administration tools.
A node communicates with external systems using an adapter built using an adapter framework. This framework defines the following concepts:
-
endpoint: this is an internal representation of a remote system. An endpoint also manages the creation and allocation of a number of sessions
-
service: a set of endpoints can be grouped into a service for administrative or operational purposes, for example, so that they can be enabled and disabled as a unit
Figure Figure 8, “Connectivity architecture” depicts the relationship between service, endpoint, and session.
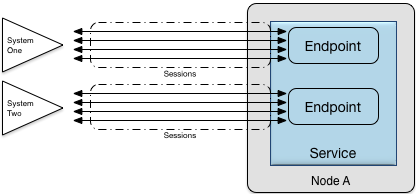
Within a node, an endpoint represents a logical destination that elements can communicate with, ignoring the intricate details of sessions and external system details. Importantly, all data format and protocol conversion between the application and the external system is done in adapters. An endpoint can manage either incoming (server) or outgoing (client) sessions.
High availability provides an easy way to ensure application availability using replicated data. Two or more nodes (generally on different machines to reduce risk) are linked together to provide redundancy for each other. Application data are replicated to one or more backup nodes depending on the availability requirements. Nodes can be configured such that all work occurs on one node with another one acting as the backup. This is called active/passive high availability. Nodes can also be configured to be simultaneously processing work. This is called active/active high availability.
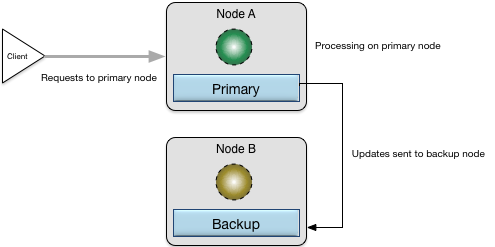
Figure 9, “High availability with primary and backup nodes active” shows two nodes configured in a primary and backup topology with a client directing traffic for processing to the primary
node (Node A). As requests are processed on the primary node, modifications, creations, updates, and deletions of application data are
transactionally replicated onto the backup node (Node B).
If the primary node goes out of service for some reason, the configured backup node takes over processing for the out-of-service node. Figure 10, “High availability with processing on backup node” shows this taking place.
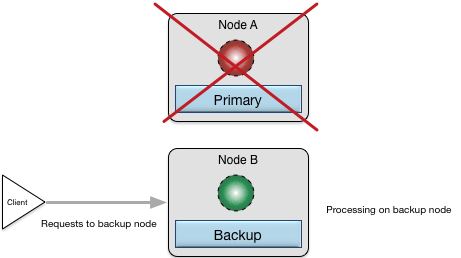
When node A is later brought back up and restored, it will again be the primary node and the processing will move back to it from node B.
It is possible to have all application processing active on one node; an alternative approach provides load balancing by allocating the application work across several nodes. It is also possible, using administration tools, to migrate processing from one node to another. This can be used to scale up a system by adding nodes, or to move processing off of a machine for maintenance reasons.