Contents
This topic explains how to use the JDBC Table data construct and one or more Query operators to access an external JDBC data source from an EventFlow module.
In an EventFlow module, a JDBC Table data construct defines a connection to the JDBC data source that you want to use. When connected to a JDBC Table icon, a Query operator can manipulate the JDBC data along with with tuples from the application's input streams. JDBC Tables can be associated with multiple Query operators, but each Query operator can be associated only with one JDBC Table.
Tip
JDBC Query operators that specify a SELECT statement generate a typecheck error when working in an environment that does not have a current connection to the database server. As a workaround, you can specify an explicit schema for the SQL query in the operator's Result Settings tab.
If you anticipate having database connectivity when composing the EventFlow module, but none later, use the Execute query and populate fields link in the JDBC Query operator. This derives the schema from running the SQL query and stores the schema for use when the operator cannot reach its configured database.
When you develop an application that uses a JDBC data source, StreamBase Studio actually connects to the database server to perform typechecking. Before performing the steps in this topic, you need the following information from the database administrator:
-
The JDBC URI to use to connect to the data source server.
-
If required, a username and password to use when connecting to the data source server.
-
The JDBC driver JAR file or files, and any native library files called by the JAR file.
-
The fully qualified class name of the driver specified in the JDBC JAR file.
You must obtain the JDBC driver JAR file or files from one of the following places:
-
From an installation of the vendor's client support package for your database, installed locally on your development machine.
-
From Maven Central or another public Maven repository, for some open source database projects that publish their JDBC drivers. MySQL is in this category.
-
From a company-specific public Maven repository, if a database vendor makes one available. Oracle drivers are in this category.
-
From the database vendor's download pages.
Remember that connecting to a JDBC data source requires:
-
Installing the JDBC JAR file or files into a Maven repository accessible to your development machine.
-
Adding a Maven dependency on those JAR files to your project.
-
Using a HOCON configuration file of type jdbcdatasource.
-
Using a HOCON configuration file of type javaengine.
Note
Under some circumstances, the JVM engine that runs your EventFlow fragment can access the wrong data source if multiple drivers attempt to access the same data source. To avoid this potential problem, it is best for all applications that access a given data source to be in the same project in a StreamBase Studio workspace.
To use a JDBC data source in an EventFlow module:
-
StreamBase Studio locates third-party JAR files that are installed into the Maven build system, as described in Using External JAR Files.
-
Your Studio project must then add a Maven dependency on these installed JAR files using > or by editing the
pom.xmlfile for your Studio project and using its Dependency tab. -
If your JDBC driver requires access to any supporting library files (such as
.so,.dynlib, orDLLfiles), specify the file system location of those using an externalNativeLibraryPath element in a HOCON configuration file of type javaengine. -
In a HOCON configuration file of type jdbcdatasource, declare the JDBC data source configuration. The following is an example for a Microsoft SQL Server 2012 database.
name = "MSsql2012" version = 1.0.0 type = "com.tibco.ep.streambase.configuration.jdbcdatasource" configuration = { JDBCDataSourceGroup = { jdbcDataSources = { mySource1 = { driverClassName = "com.microsoft.sqlserver.jdbc.SQLServerDriver" serverURL = "jdbc:sqlserver://mssql2012.lab.streambase.com\\DBname" userName = "user" password = "Secr3t1ve" operationTimeoutMilliseconds = 200000 batchTimeoutMilliseconds = 60000 connectionTimeoutMilliseconds = 50000 queryTimeoutMilliseconds = 10000 fetchSize = 10000 operationBatchSize = 20 maxColumnSizeBytes = 32768 operationBatchSize = 20 } } } }The name you assign in your data source configuration file must follow the StreamBase identifier naming rules, as described in Identifier Naming Rules.
You can use an encrypted password, as described on Encrypting Sensitive Configuration Data.
-
Drag a JDBC Table icon from the Palette view to the EventFlow canvas.
-
Open the Properties view of the new JDBC Table data construct. Name the component in the General tab, and in the Data Source tab, identify the data source this table will use. If no data sources appear in the dropdown list in this tab, this means you have not completely configured the server configuration file as described in the jdbcdatasource reference page, or that the configuration file is invalid.
-
Create one or more Query operators that will be associated with the JDBC Table. That is, for each query, drag a Query operator icon from the Palette view to the canvas.
-
Connect the Query operators to the JDBC Table. If automatic typechecking is enabled, StreamBase Studio performs typechecking at this point.
If a typecheck error reports an unknown data source:
-
Make sure the database server is running and is accepting connections.
-
Double-check your entries in the configuration file and make sure the JAR file that implement JDBC access to your database is installed and available to your EventFlow project as described in Using External JAR Files.
-
-
For each Query operator, edit its properties as described in Using the Query Operator with JDBC Tables.
StreamBase provides several options to manage the behavior of your JDBC connections. For example, if your application needs to access more than one JDBC data source, you can provide a different set of options for each JDBC data source by specifying a single HOCON configuration file for your JDBC data sources. If your Query operators need to share the same JDBC data source, you can configure connection pooling to do so.
See the jdbcdatasource reference page for the available JDBC data source options.
Different JDBC drivers allocate different sizes for column types. Very large column types (such as the text column for the Microsoft JDBC driver) can cause typecheck errors. For this reason, the JDBC configuration file can set a maximum column size for JDBC tables. By default, this parameter is set to 2048.
If your JDBC database uses wide column types, there are several options to avoid typecheck problems in StreamBase:
-
Limit column sizes in the SQL statements of individual Query operators in EventFlow modules. As long as you specify a column size of 2048 or less, output tuple sizes will be acceptable. The SQL syntax depends on your database; here are three different examples of setting a column size to 1000:
select cast(large_col as varchar(1000)) from table select substr(large_col,1,1000) from table select convert(large_col,varchar(1000)) from table
Note
If the actual data in your columns exceeds the limit you set, the data will be truncated.
-
Set the maximum column size to a higher value. Open the configuration file, and add a
maxColumnSizeBytesparameter, and set the value. For example:maxColumnSizeBytes = 32768
This setting applies to all JDBC tables connected to this EventFlow module.
If neither of these options is acceptable, consider changing your JDBC table schema to avoid wide column types.
Recall that StreamBase Studio communicates with the data source server in order to typecheck an application that has a JDBC
data source connection. If the data source server does not respond during a preset operationTimeoutMilliseconds interval, the application fails to typecheck.
The default timeout value of 15 seconds is adequate for normal local area network connections. Consider increasing the operationTimeoutMilliseconds interval in your JDBC configuration file if you experience typecheck failures due to a slow network connection.
You may need to repeat this process, trying different operationTimeoutMilliseconds values, until your application typechecks normally.
It is possible for deadlocks to occur if you perform multiple query operations against the same JDBC data source, and when the output of one query operation feeds the input of another. By default, when multiple EventFlow Query operators connect to the same JDBC Table, all the query operations run in the same thread, and each query operation holds a connection to the external data source. Therefore, a deadlock can occur if the following conditions are all true:
-
The fragment contains a path running on a single thread with a Query operator connected to a JDBC database.
-
The query returns more than one row from one or more tables.
-
On the same path and in the same thread, a downstream Query operator attempts to update one or more of the selected JDBC tables.
Note
When we refer to a JDBC Query operator, we mean a Query operator that is connected to a JDBC Table data construct, which in turn is configured to connect to an external database.
For example, consider the following EventFlow module, where the first Query operator is used to read data from a large result set in a JDBC table. The second Query operator consumes those output tuples and then attempts to update the same JDBC table rows:
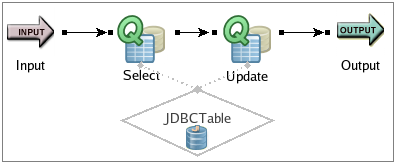 |
In this scenario, if the first query runs to completion first (all rows in the result set are fetched), the second query can run without a problem.
Now, consider what happens if the Select operator passes only a partial result set in its first output tuple to the Update operator. Because the select operation is not finished, the JDBC server forces the Update operator to wait. The Update operator cannot write to the data source while the JDBC server is waiting. Meanwhile, the Select cannot finish fetching rows because the thread shared by the two operators is waiting for the update operation.
To avoid this issue, you can take any one of these steps:
-
Redesign your application to eliminate multiple query operations on the same data source. This might involve writing more complex SQL update operations that select as well as update data. For example, combine the operations into a single Query operator, and within the updating expression use UPDATE ... WHERE.
-
Write a Query that will return a result set (per SELECT) that is less than the configured
fetchSizeparameter. Most JDBC drivers have a default fetch size that is larger than 1, but the actual value varies in different JDBC drivers. Consider explicitly setting thefetchSizeparameter in your JDBC configuration file. This parameter attempts to specify the size of the buffer used by the JDBC driver when fetching rows during query execution. Decide on the minimum number of tuples that you can reasonably fetch from the database per query, and then make sure thatfetchSizeis set to a larger value. -
Process one or more of the Query operations in parallel mode instead of the default serial mode, if feasible for your application, as described in Concurrency Options.
Multiple operators in multiple threads can conflict, but they will usually succeed eventually, because StreamBase retries the SQL statement that fails. In general, one way to work around deadlocks is to put operations in separate threads.
Queries to some external JDBC data sources can produce very large result sets. If a SELECT statement returns too much data,
memory can be exhausted. If the problem cannot be addressed in the JDBC data source itself, consider setting the fetchSize parameter in JDBC configuration file.
This parameter attempts to limit the size of the buffer used by the JDBC driver when fetching rows during query execution. The use and effects of this parameter vary in different JDBC drivers.
If you know that the database may return an exception due to transaction deadlocks in the database, and the expected behavior of your JDBC server is to roll back the operation or transaction and retry, consider enabling your EventFlow fragment to detect such exceptions for a select, insert, or update query.
To use the retry feature, specify a retrySQLStateValues parameter in your JDBC configuration file.
If the database driver returns a SQLSTATE code of 40001, the EventFlow fragment retries the query.