Contents
Standard StreamBase provides both Data File and JDBC options to specify a source for a stream of input tuples for testing your StreamBase application in a feed simulation. As an alternative, you can write custom Java file reading code to read non-standard, proprietary, or binary files as the source of your feed simulation's input tuples. StreamBase provides a way to use your custom code instead of its internal CSV-reading code in conjunction with the Feed Simulation Editor's Data File option.
In many cases, the column mapping and timestamp conversion options in the Data File Options dialog are flexible enough to adapt or convert any format CSV file for use as a feed simulation input. Most data feeds can be converted to CSV format. You only need to consider writing a custom file reader is cases where your data feed is available in a proprietary or binary file format and converting to CSV would slow down the feed simulation, or when you need to adjust a non-standard CSV file.
Your custom file reading code must extend one of the classes in the com.streambase.sb.feedsim package in the StreamBase Client Library, as described on this page.
You must place the class file containing your feed simulation custom reader on the classpath of the JVM that runs StreamBase Studio and the sbfeedsim command. The classpath must be configured before you start Studio.
Use the STREAMBASE_FEEDSIM_PLUGIN_CLASSPATH environment variable or the streambase.feedsim.plugin-classpath Java system property to specify the path to a package directory or JAR file that contains your custom class. If your development
environment or your application requires more than one custom file reader class, specify the paths as a list separated with
semicolons (Windows) or colons (UNIX).
Use the Custom reader button in the Data File Options dialog to specify the fully qualified name of your custom Java class. The dialog shows an error message if it cannot locate your custom class.
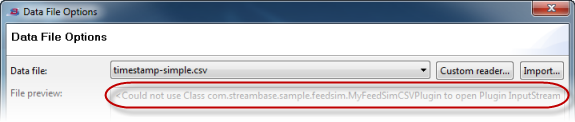 |
This error message is resolved with the following steps:
-
Exit Studio.
-
Set the
STREAMBASE_FEEDSIM_PLUGIN_CLASSPATHenvironment variable to the location of your custom file reader class. -
Restart Studio:
-
If you set the environment variable temporarily in a terminal window or StreamBase Command Prompt, then restart Studio from that command prompt with the sbstudio command.
-
For Windows, if you set the environment variable globally, then restart Studio from its icon.
-
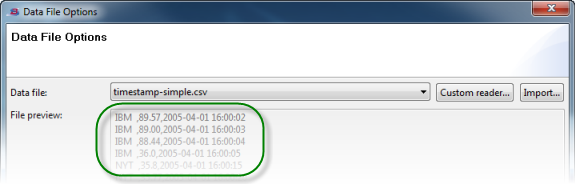
When Studio can locate your custom class, it shows the contents of the selected file in the File preview grid of the Data File Options dialog:
 |
Consider the following points when setting your custom reader classpath:
-
While developing your custom reader, set the environment variable to the
java-bindirectory of your Studio project, so that you can test your class without stopping to generate a JAR file. Studio automatically and silently compiles Java source files in a project'sjava-srcdirectory and places the resulting class files in thejava-bindirectory. (Studio does not display thejava-bindirectory in the Project Explorer view.)For example, for Windows:
set STREAMBASE_FEEDSIM_PLUGIN_CLASSPATH= C:\Users\sbuser\Documents\StreamBase Studio 11.2 Workspace\MyCustomReaderProject\java-bin
For Linux and Bash:
export STREAMBASE_FEEDSIM_PLUGIN_CLASSPATH= \ /home/sbuser/StreamBase Studio 11.2 Workspace/MyCustomReaderProject/java-bin
-
To share a completed custom reader class with other developers and testers, use Studio to save the
java-bindirectory as a JAR file. Then specify the path to the JAR file like these examples:For Windows:
set STREAMBASE_FEEDSIM_PLUGIN_CLASSPATH=C:\SBappSupport\MyCustomReader.jar
For Linux and Bash:
export STREAMBASE_FEEDSIM_PLUGIN_CLASSPATH=/home/sbadmin/sbappsupport/MyCustomReader.jar
StreamBase provides a sample showing two implementations of a custom file reader. See Feed Simulation Custom Reader Sample for instructions on loading and running the sample.
Your custom file reader class must extend one of the classes in the com.streambase.sb.feedsim package in the StreamBase Java Client Library. See the Javadoc for these classes in the Java API Documentation. You can extend one of two classes:
-
FeedSimCSVInputStream
-
FeedSimTupleInputStream
The class FeedSimCSVInputStream itself extends java.io.InputStream, from which it inherits its read() method. This class reads a specified file and passes its contents to the feed simulation mechanism a character at a time.
This is the class to extend in the majority of custom file reader cases.
When extending the FeedSimCSVInputStream class, you must:
-
Provide a constructor that provides a string path to a file.
-
Provide an override of the
read()method that returns a character.
When using a custom reader class that extends the FeedSimCSVInputStream class, the Data File Options dialog uses the read() method of your class to display the contents of your data file in the File preview grid. All the options in the Data File Options dialog and Feed Simulation Editor are available when using a custom reader
that extends the FeedSimCSVInputStream class.
For an example, see MyFeedSimCSVPlugin.java in the Feed Simulation Custom Reader Sample.
The class FeedSimTupleInputStream extends FeedSimCSVInputStream. This class reads a specified file and passes its contents to the feed simulation mechanism a tuple at a time. Extend this
class as a higher performance option, but only if the format of your data file is amenable. If your data file format is a
CSV-like text format, there is no advantage in converting the data to tuples for the feed simulation. For binary files or
very complex text files, however, this class can offer a performance advantage.
When extending the FeedSimTupleInputStream class, you must:
-
Provide a constructor as described for the
FeedSimCSVInputStreamclass. -
Provide a
getSchema()method. -
Provide a
readTuple()method.
Consider the following limitations when extending the FeedSimTupleInputStream class:
-
The File preview text area of the Data File Options dialog uses the
read()method of your class to display the preview, not thereadTuple()method. Thus, the file preview may not match what your class delivers to the feed simulation. -
The grid in the center of the Data File Options dialog shows a limited number of the initial Tuples produced by your class. The header row of that grid shows the names of the tuple fields as determined by the Schema returned by the
getSchema()method of your class. -
The Column mapping grid at the bottom of the Data File Options dialog can be used to map tuple fields to fields in the stream being fed by the feed simulator. The mapping works the same way as mapping data from a CSV file that has a header, except names come from the
getSchema()result and not from a CSV header row. The mapping grid is useful in cases where the field names in the Schema do not match output field names exactly, or if the order of fields does not match by chance.
For an example, see MyFeedSimTuplePlugin.java in the Feed Simulation Custom Reader Sample.